
 par
par Suite à l’annonce d’Apple de pouvoir faire fonctionner un LLM sur ses iPhones, je voulais tester la réelle faisabilité de la chose sur un device Apple Silicon (Puce A17) très portable : j’ai donc pris mon téléphone. J’ai pu trouver un process pour le faire… et je vous le partage ici. J’ai fait le test avec un modèle Mistral-7B-Instruct-v0.2 (format GGUF) qui en gros fournit un équivalent de GPT3.5 grâce à la start-up française Mistral (cocorico !). Cela fonctionne parfaitement !!
ATTENTION : cela pousse fortement l’appareil (et consomme beaucoup de batterie). A ne réserver qu’aux appareils récents et évidemment je décline toute responsabilité des conséquences des manipulations que vous feriez.
Si vous êtes prêt à tenter l’aventure, voici la manière de faire, en 4 (presque) petites étapes.
1. Télécharger l’application pour faire tourner des LLM open source
Cette application s’appelle LLM Farm (disponible ici : https://llmfarm.site/) et depuis deux semaines directement accessible via l’AppStore : https://apps.apple.com/us/app/llm-farm/id6461209867.
LLMFarm est en effet une application iOS et MacOS permettant de travailler avec de grands modèles de langage (LLM). Elle vous permet de charger différents LLM avec d’assez nombreux paramètres. Notamment, cela supporte déjà pas mal de fonctionnalités (pour une version encore en v0.8 !) : différentes inférences, diverses méthodes d’échantillonnage, mode Métal, modèles de configuration du modèle, support des adaptateurs LoRA, LoRA finetune et Export.
L’application s’installe rapidement et classiquement.
2. Télécharger un modèle de LLM (pas trop gros)
J’ai pris le modèle Mistral-7B-Instruct-v0.2 au format GGUF qu’on trouve sur HuggingFace (taille de 4Go), et plus précisément dans le répertoire de TheBloke : https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.2-GGUF/tree/main. Il faut avoir autour de 4.5Go de disponible sur l’appareil (et une connexion raisonnable pour le télécharger, privilégiez le wifi). Au passage grand bigup à Hugging Face pour l’immense travail de repository qui est super propre !
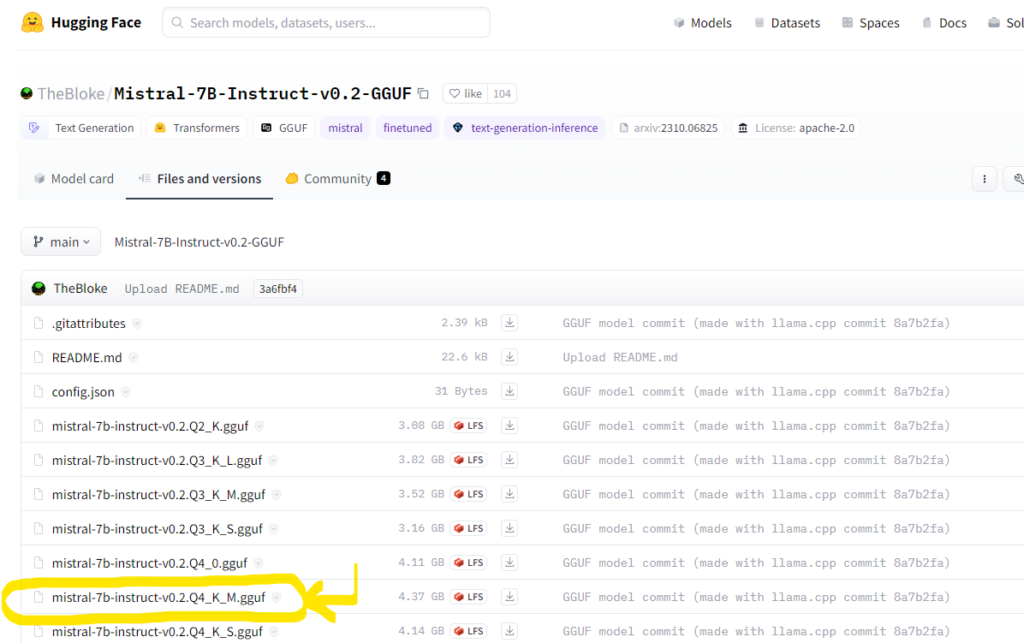
Sur votre téléphone, une fois chargé, le modèle se trouve dans vos téléchargements. Il est mieux de le copier alors dans le répertoire « models » de LLM Farm auquel vous accéderez via l’application Fichiers > Sur mon iPhone.
De la sorte, LLM Farm le trouvera facilement. Pour copier votre modèle, vous allez dans Téléchargements et vous le déplacer vers Sur mon iPhone > LLM Farm > Models. Pensez, si vous n’avez pas fait déplacer à effacer le téléchargement car il prend aussi 4.4 Go (et l’app le copie dans son répertoire) !!!
3. Paramétrage de LLM Farm pour utiliser Mistral-7b
On attaque la phase de paramétrage de l’outil… c’est un peu long, mais j’ai essayé de vous rendre ça facile d’accès et facile à lire. Vous me direz si certains points ne sont pas clairs.
3.1 Charger un nouveau modèle LLM
Pour cela, vous lancez l’application et vous allez sur Add Chat et vous arrivez sur cet écran :
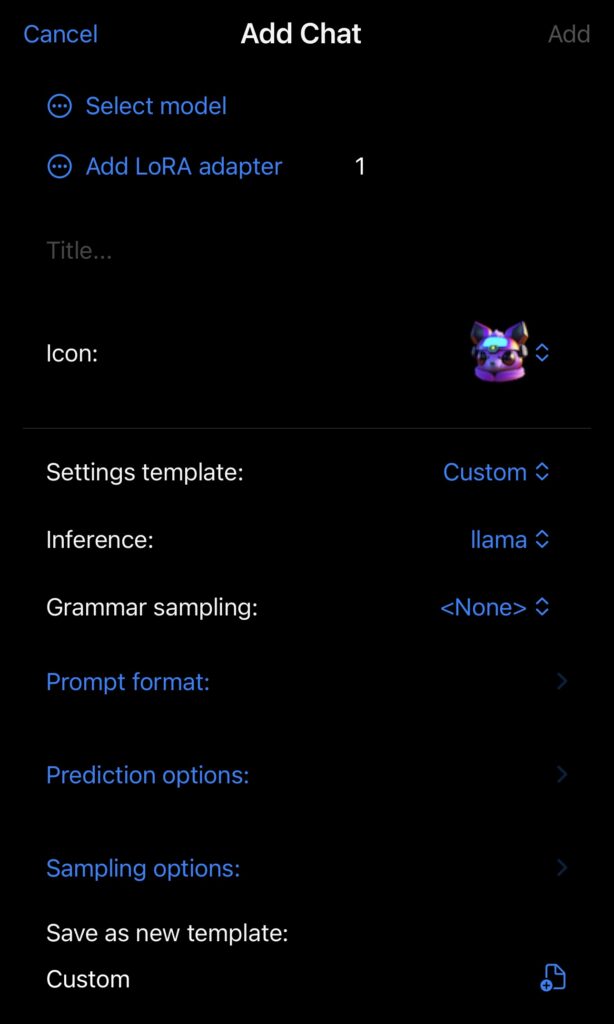
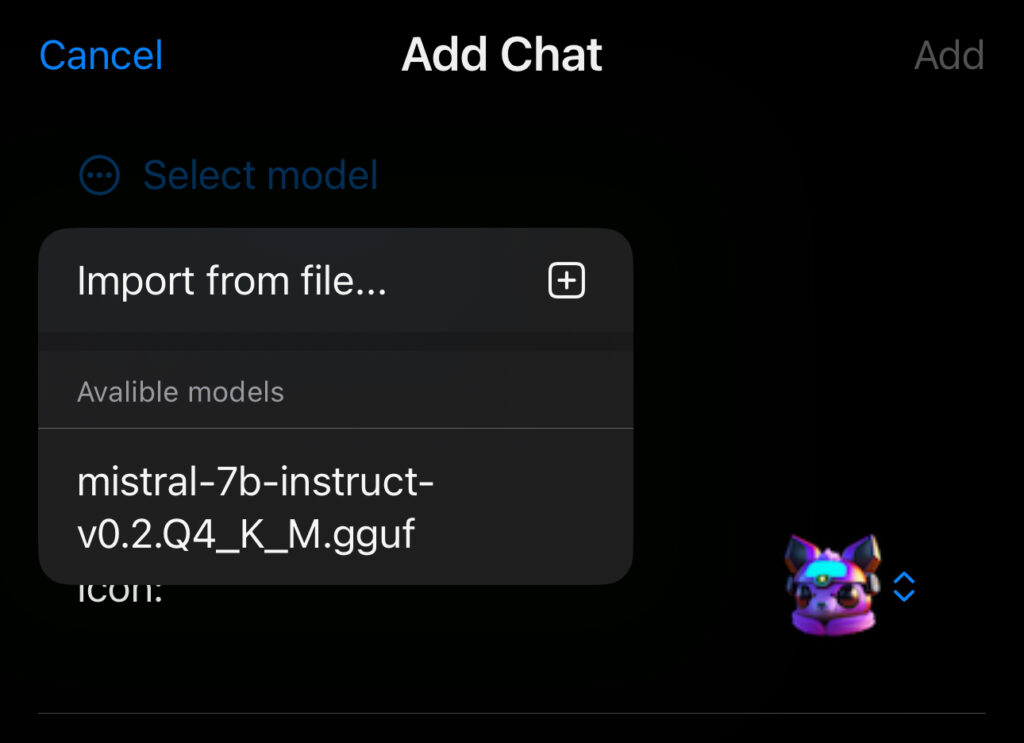
Vous cliquez alors sur Select model et il vous propose « Import from file… » et vous ouvre les modèles disponibles dans le répertoire models de l’app. Une fois le fichier « chargé », il apparaît dans la liste des « available models ». Votre écran doit ressembler à ça :
3.2 Configurer le Chat
Maintenant que le modèle est chargé, c’est la toute dernière étape : la configuration du chat pour pouvoir interagir avec le modèle. Cela se passe à la suite de l’écran… en dessous de l’icon de LLM Farm.
On laisse tout ça, sans rien toucher : Settings template : Custom, Inference : LLaMA, Grammar sampling : none.
Par contre, il faut bien mettre le format du prompt comme indiqué par la documentation de Mistral (pour cela vous enlevez le format par défaut), et vous mettez :
<s>[INST] {{prompt}} [/INST]
Votre écran doit ressembler à ça désormais :
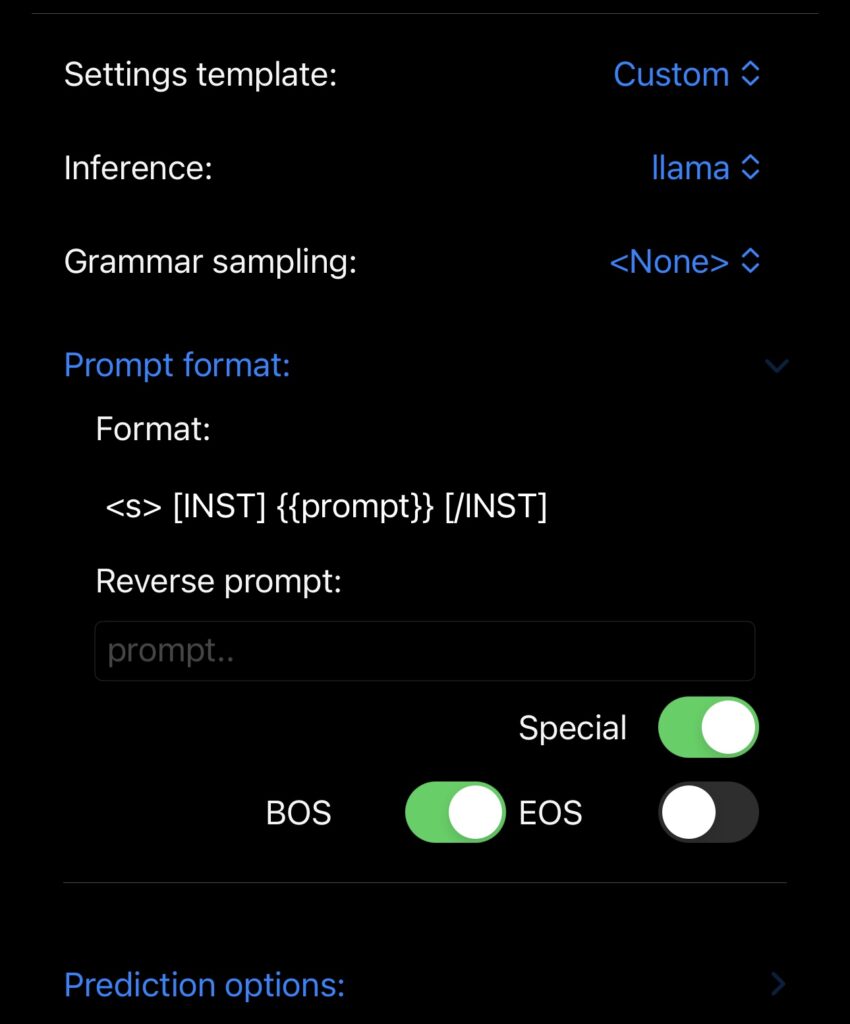
Il reste encore quelques paramétrages à gérer pour tirer le meilleur parti de votre appareil Apple.
Pour cela, il faut aller dans la rubrique située juste en dessous Prediction options pour choisir les options : Metal afin de tirer partir de la puce Apple Silicon (A17 ou M3 notamment). J’ai également mis MLock et MMap (bien que sur iPhone), mais ça semble mieux réagir sans MLock (notamment pour fermer l’app si elle se fige). Voilà donc à quoi ressemblait mes paramétrages :
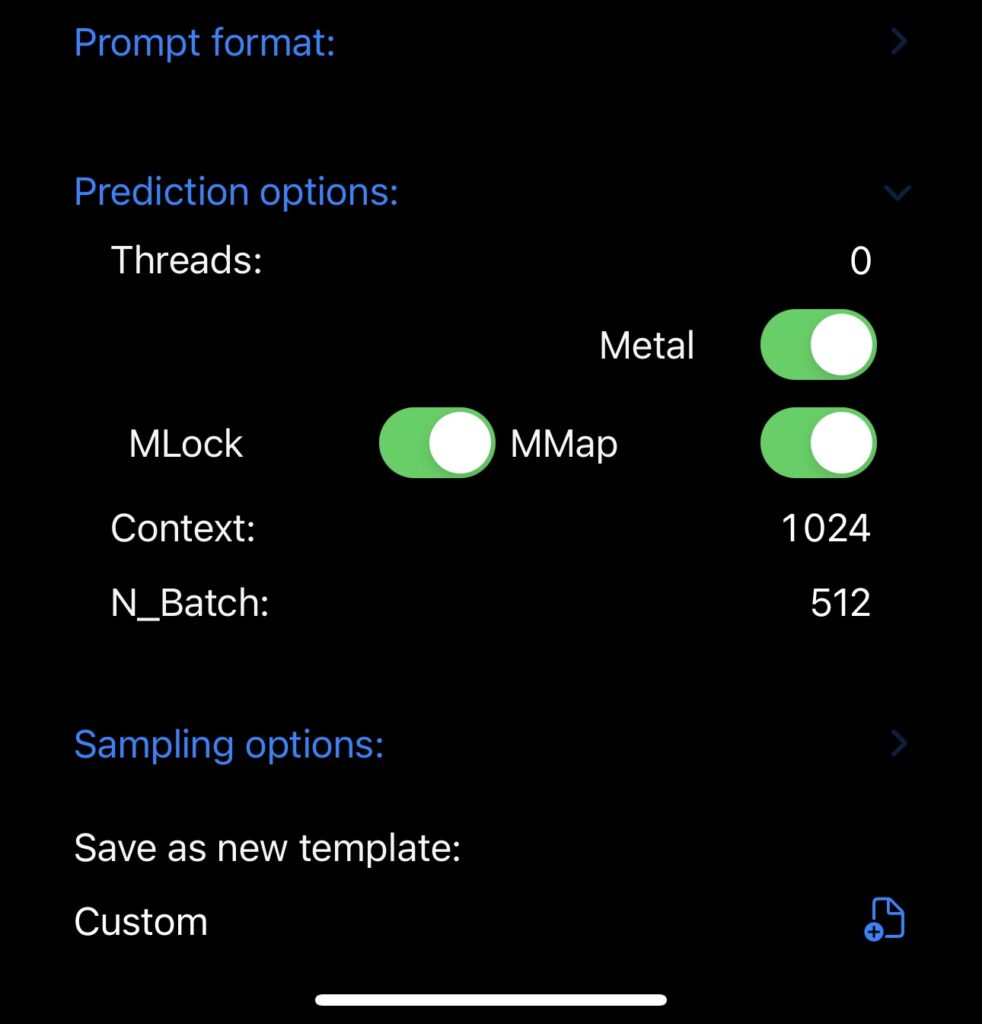
Une fois tout cela fait, vous pouvez cliquer sur Add (ou Save si vous avez quitté l’écran sans avoir fini le paramétrage).
4. LE TEST de votre LLM Mistral en local
Ca y est, si vous avez tout bien suivi, vous allez enfin pouvoir faire tourner votre LLM en local. A ce stade vous pouvez mettre en mode avion, le modèle est en local et n’a donc pas besoin d’internet pour fonctionner. Vous allez pouvoir écrire vos prompts, et regarder les réponses sur votre téléphone, en mode avion (voir la photo ci-dessous prise en cours de calcul de la réponse)
Un conseil : faites des prompts « raisonnables » car sinon le temps de calcul peut être long… et comme l’appareil est beaucoup sollicité, pas facile de couper la réponse. Là 10 lieux c’est un peu trop par exemple !
Nota bene : sur le premier prompt, il y a une période de « chargement du modèle » qui peut durer un peu (et sembler longue tant on est impatient de tester). Sur les suivants, la réponse est plus rapide car ce chargement « model loading » n’est plus d’actualité.
5. Impressions et étapes suivantes ?
Vous l’aurez compris, on en est encore qu’au tout début de tout ça. Toutefois, cela donne concrètement une vision assez claire de ce qui va arriver très vite (au plus tard 2025 d’après Apple, et là WWDC24 de Juin 2024 avec iOS18 risque d’être très très intéressante sur ce volet). Voici quelques impressions suite à mes tests :
Alors la première impression, c’est qu’évidemment le paramétrage prend un peu de temps et l’interface est surtout nouvelle (mais les réglages sont assez « classiques » quand on traite de ces sujets) car pour la première fois sur « petit écran ».
La seconde impression, c’est l’excellente surprise de réactivité de la puce A17 car… tout de même c’est un GPT3.5 sur un « petit device ». Certes le modèle est optimisé et le device aussi, mais justement cela ouvre des perspectives fascinantes quant à la réelle consommation énergétique future des LLM… elle va fortement diminuer à mon sens. Toutefois, on sent tout de même qu’on tire le maximum des capacités de l’appareil, je réitère donc mon warning (à ne pas tenter sur n’importe quoi) :
ATTENTION : cela pousse fortement l’appareil (et consomme beaucoup de batterie). A ne réserver qu’aux appareils récents et évidemment je décline toute responsabilité des conséquences des manipulations que vous feriez.
Ma troisième impression c’est que les modèles quantifiés sont hyper intéressants car offre des performances similaires à ce qu’on avait il y a un an au moment de la sortie de ChatGPT pour des tailles bien inférieures ! C’est également de bon augure pour l’évolution de cette technologie.
Nota bene : qui dit performance d’il y a un an, dit … beaucoup plus d’hallucinations que maintenant (vs. GPT4 dont le niveau de réponse reste pour moi LA référence à date). Ainsi, le classique « test de la bio perso » a été un désastre complet, je suis devenu artiste peintre et sculpteur né en 1953 ! VIGILANCE donc ! ^ ^
Ma quatrième impression c’est que l’air de rien, on fait tourner un modèle créé par une entreprise française et ça aussi c’est une excellente nouvelle : Paris est une très belle place pour avancer sur l’IA et Mistral un lieu qui semble particulièrement intéressant au regard des premiers résultats.
Ma dernière impression c’est que le moment où Apple va décider d’intégrer son LLM optimisé pour ses puces sur son OS et ses appareils, ça va être assez fort… reste à voir jusqu’où ils arriveront à descendre en « rétro compatibilité » tout en gardant les données sur l’appareil pour monter en personnalisation (tout en garantissant de la confidentialité donc, puisque non géré en dehors du device). Peut-être que 2024 répondra à cette question ! Vivement l’été !
Remerciements : ce tuto est adapté à la version actuellement dispo de l’app (v. 0.8) sur l’App Store (donc sans tout le bazar du TestFlight), inspiré de celui en anglais par Maciek Jędrzejczyk et disponible ici. Merci à lui !

Bonjour Alain,
Merci beaucoup pour ce tutoriel il était extrêmement clair et c’est fait très rapidement moins de cinq minutes. Il faut juste ouvrir l’application une première fois afin que le dossier puisse se créer.
Sinon, tout le reste était parfait.
Un vrai plaisir de découvrir ce blog pour la première fois.
Tu as gagné à nouveau Followers.
Bonne journée 😉