 par
par Le 5 mars 2026, Anthropic a publié un rapport de recherche intitulé Labor market impacts of AI: A new measure and early evidence, signé par Maxim Massenkoff et Peter McCrory. Ce document propose une approche inédite pour mesurer l’exposition réelle des métiers à l’intelligence artificielle, en distinguant ce que l’IA pourrait théoriquement faire de ce qu’elle fait effectivement dans les usages professionnels observés. C’est un travail rigoureux, ancré dans les données, qui mérite qu’on s’y attarde, autant pour ce qu’il nous apprend que pour ce qu’il laisse dans l’ombre.
Les grands enseignements du rapport
Une nouvelle mesure : l’« observed exposure »
La contribution centrale du rapport est l’introduction d’une mesure baptisée observed exposure (exposition observée). Contrairement aux indices d’exposition habituels, fondés uniquement sur les capacités théoriques des LLM (comme le β d’Eloundou et al., 2023), cette mesure croise trois sources de données : la base O*NET qui recense les tâches de près de 800 métiers aux États-Unis, les données d’usage réel de Claude issues de l’Anthropic Economic Index, et les estimations théoriques de faisabilité par un LLM de chacune de ces tâches.
L’idée est simple mais puissante : un métier est davantage exposé si ses tâches sont non seulement théoriquement réalisables par l’IA, mais aussi effectivement observées dans des contextes professionnels, et ce de manière automatisée plutôt qu’augmentative. Les usages via API ou workflows automatisés comptent davantage que l’utilisation conversationnelle par un humain.
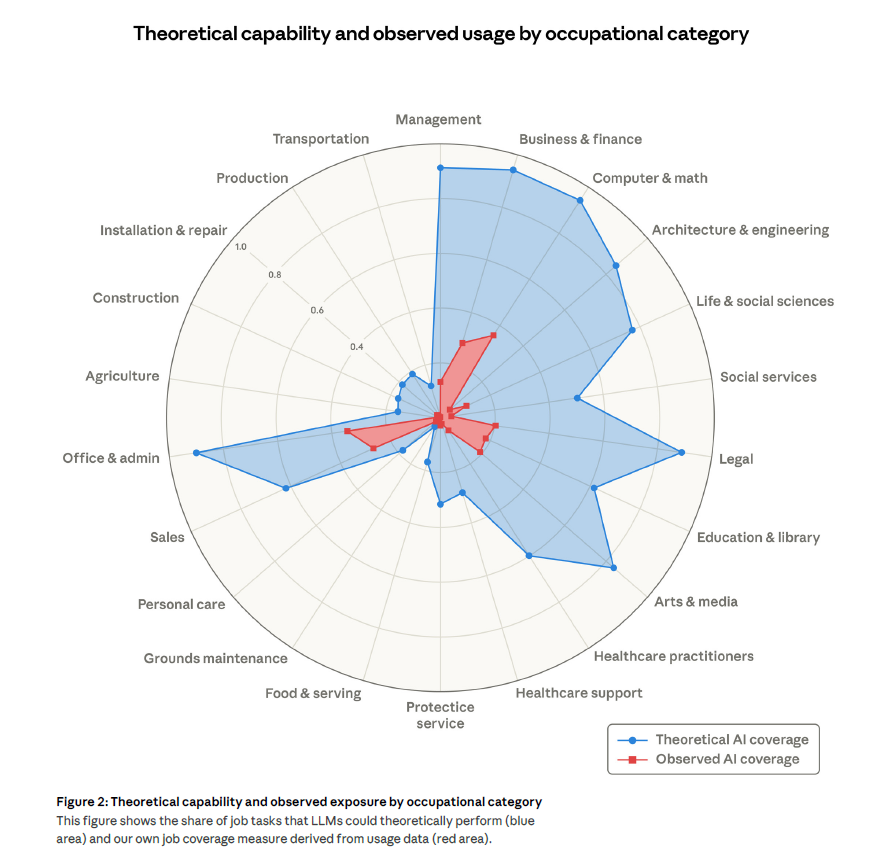
L’écart entre théorie et réalité est considérable
L’un des résultats les plus frappants : l’IA est très loin d’exploiter son potentiel théorique. Dans la catégorie « Computer & Math », par exemple, 94 % des tâches sont théoriquement réalisables par un LLM, mais seules 33 % sont effectivement couvertes dans les données d’usage. Cet écart massif se retrouve dans presque toutes les catégories professionnelles, des métiers juridiques aux postes administratifs. Les raisons sont multiples : contraintes réglementaires, nécessité de vérification humaine, limites des modèles actuels, ou tout simplement lenteur de diffusion.
Les métiers les plus exposés
Le rapport identifie les dix métiers les plus exposés selon cette nouvelle mesure. En tête, les programmeurs informatiques affichent un taux de couverture de 74,5 %, leur tâche principale — écrire, mettre à jour et maintenir des programmes, étant massivement observée dans les usages de Claude.
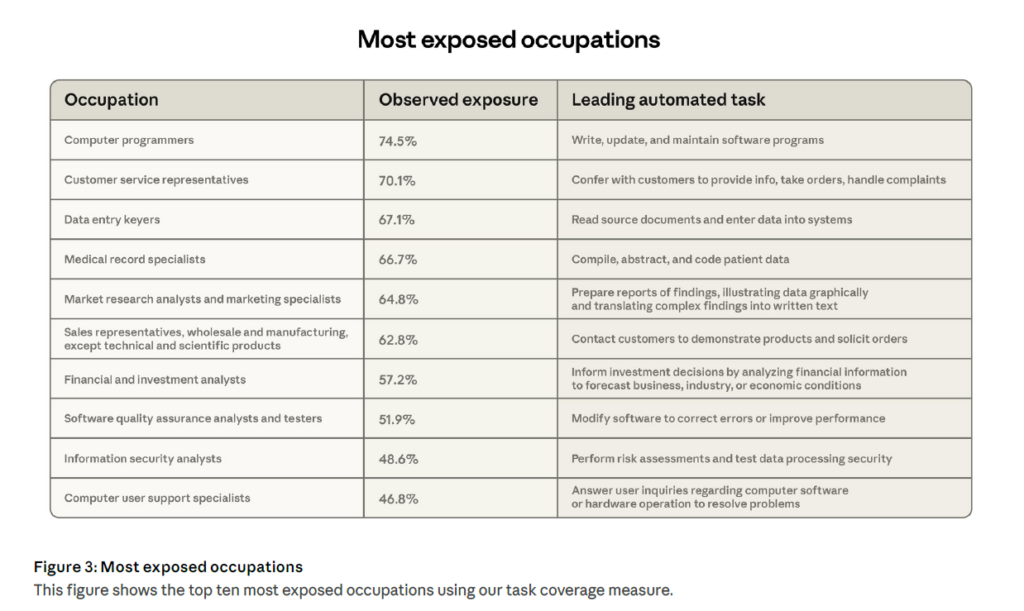
Suivent les représentants du service client (70,1 %), dont les interactions avec les clients sont de plus en plus prises en charge par des flux API automatisés. Les opérateurs de saisie de données (67,1 %), les spécialistes des dossiers médicaux (66,7 %), les analystes en marketing (64,8 %), les commerciaux (62,8 %), les analystes financiers (57,2 %), les testeurs logiciels (51,9 %), les analystes en sécurité informatique (48,6 %) et les spécialistes du support informatique (46,8 %) complètent ce classement.
Les métiers les plus protégés
À l’autre extrémité du spectre, 30 % des travailleurs américains ont un taux de couverture nul : leurs tâches apparaissent trop rarement dans les données d’usage pour atteindre le seuil minimal. Parmi eux : cuisiniers, mécaniciens moto, sauveteurs, barmans, plongeurs, habilleurs. Ce sont essentiellement des métiers physiques, manuels ou relationnels de proximité — le type de travail que l’IA est très loin de pouvoir remplacer.
Un profil-type du travailleur exposé
Les travailleurs les plus exposés ne sont pas ceux qu’on imagine souvent. Comparés au groupe non exposé, ils sont en moyenne 16 points de pourcentage plus susceptibles d’être des femmes, 11 points plus souvent blancs, et presque deux fois plus souvent d’origine asiatique.
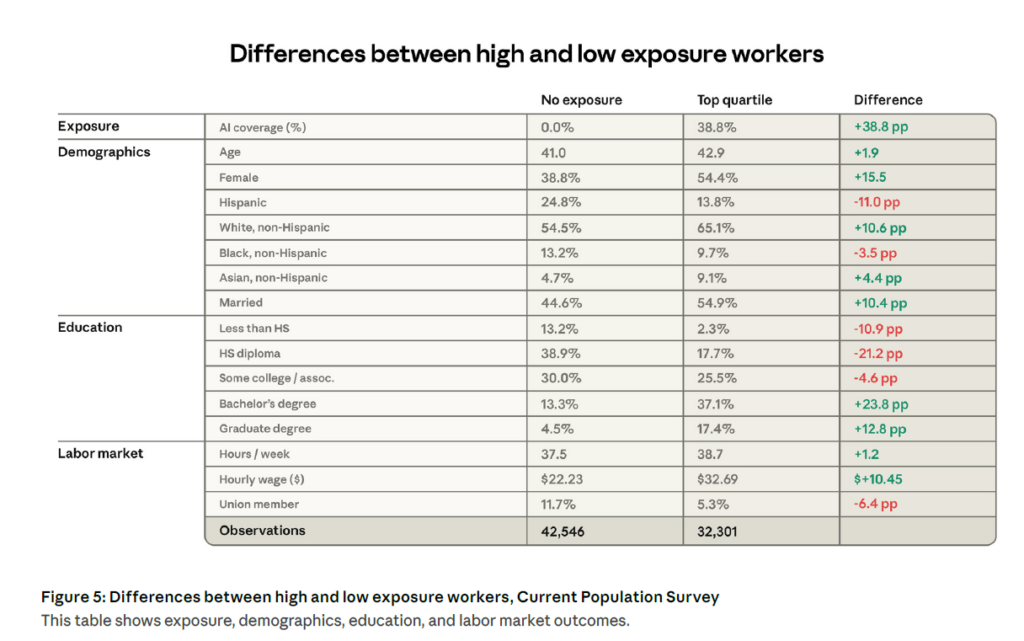
Ils gagnent en moyenne 47 % de plus (32,69 $ contre 22,23 $ de l’heure). Et leur niveau d’éducation est nettement supérieur : 17,4 % détiennent un diplôme de cycle supérieur dans le groupe exposé, contre 4,5 % dans le groupe non exposé, un rapport de près de un à quatre.
Pas (encore) d’effet sur le chômage, mais un signal sur les jeunes
Le résultat le plus rassurant, et pas si surprenant que ça, du rapport est l’absence d’effet mesurable sur le taux de chômage des travailleurs exposés depuis la sortie de ChatGPT fin 2022. L’analyse en différences de différences ne révèle aucune divergence statistiquement significative entre le quartile le plus exposé et le groupe non exposé, avec un coefficient de +0,0020 (écart-type 0,0019), indiscernable de zéro.
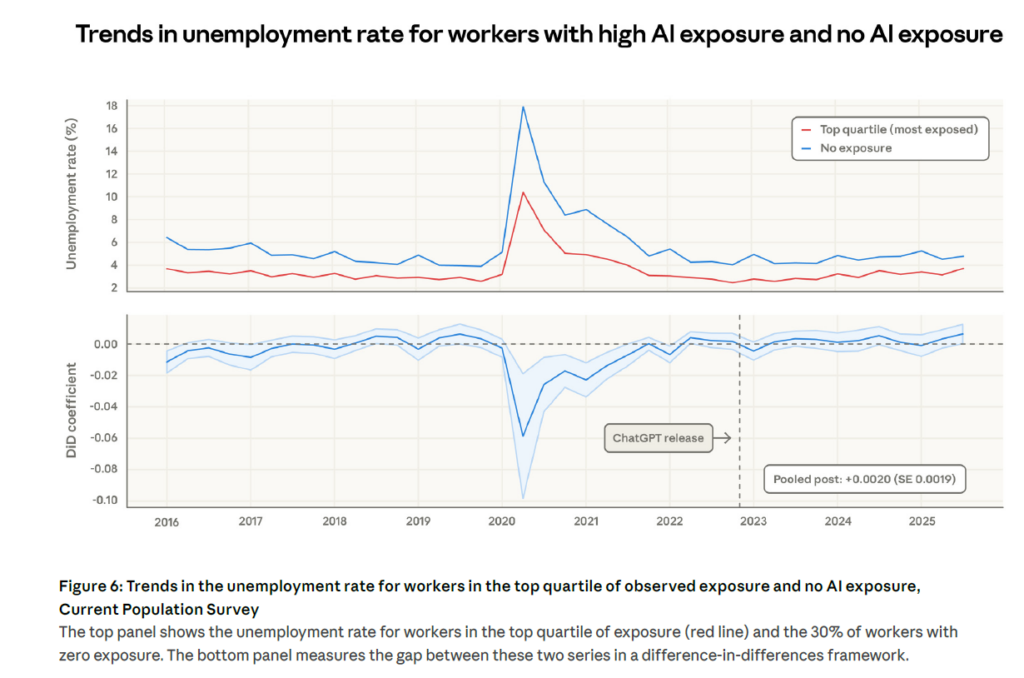
En revanche, un signal plus inquiétant émerge pour les jeunes travailleurs de 22 à 25 ans. Le taux d’entrée dans un nouvel emploi dans les métiers exposés a diminué d’environ 14 % par rapport à 2022, un résultat à peine statistiquement significatif mais qui converge avec les travaux de Brynjolfsson et al. (2025) à partir des données ADP.
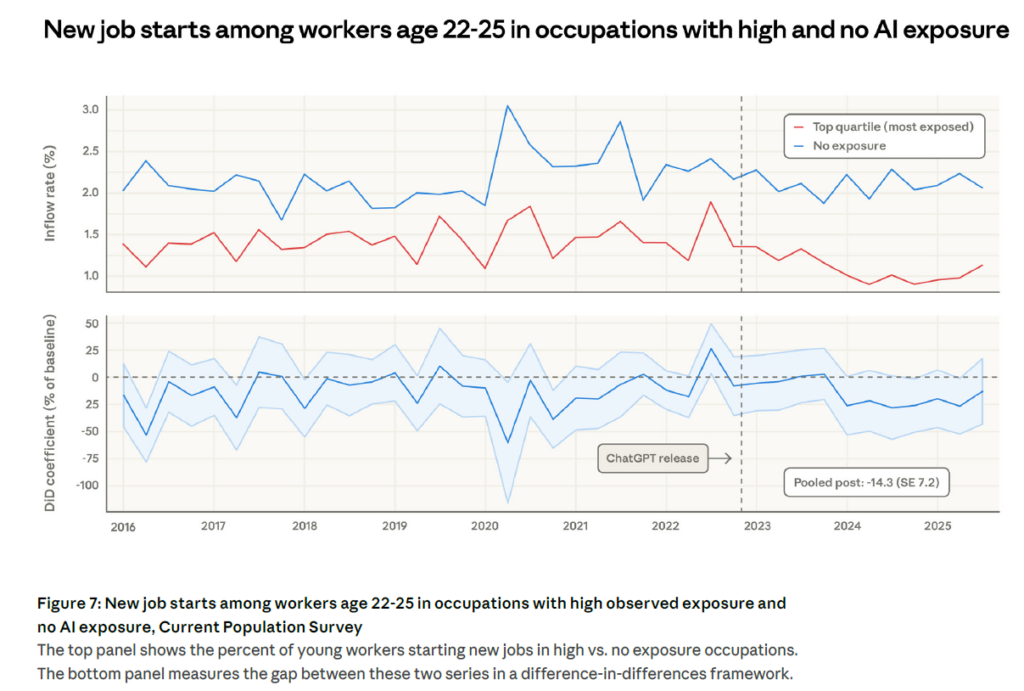
Ce n’est pas tant que les jeunes perdent leur emploi, mais plutôt qu’ils semblent ne pas être embauchés dans les métiers les plus touchés. C’est donc un phénomène de ralentissement du recrutement plutôt que de licenciement… qui expose de facto toute une génération de diplômés qui arrivent actuellement sur le marché du travail !
L’exposition observée prédit (un peu) les projections du BLS
Les auteurs montrent une corrélation modeste mais réelle entre leur mesure d’exposition et les projections d’emploi 2024-2034 du Bureau of Labor Statistics : pour chaque augmentation de 10 points de pourcentage de la couverture observée, la projection de croissance de l’emploi diminue de 0,6 point.
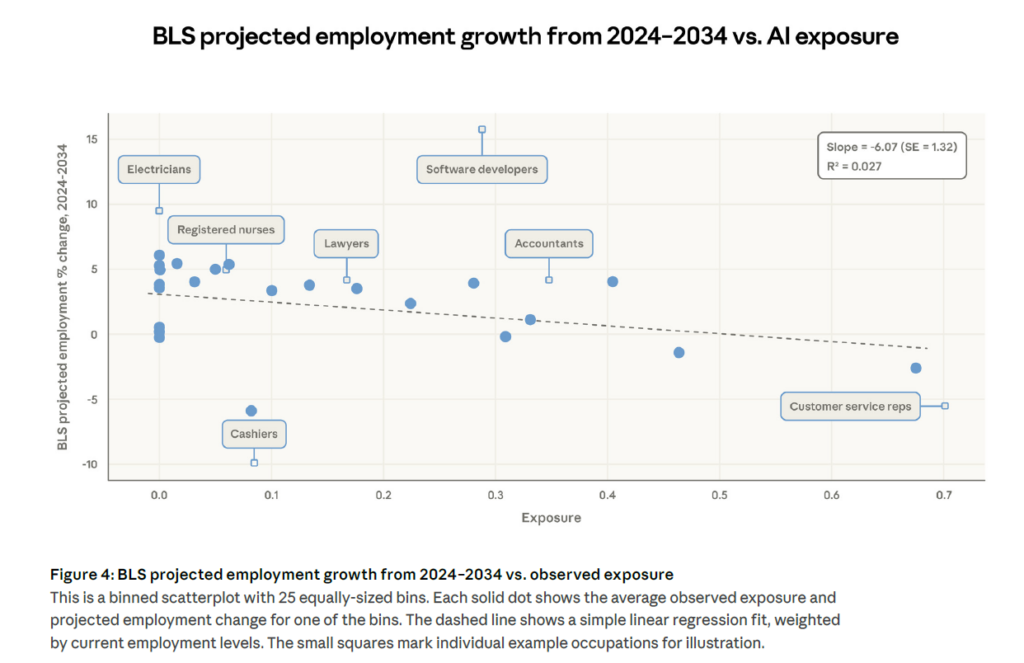
Le R² reste faible (0,027), mais cette corrélation n’existe pas avec la mesure théorique d’Eloundou et al. seule, ce qui valide l’apport de la dimension « usage réel ».
Analyse critique : ce que le rapport d’Anthropic ne dit pas (encore)
Un biais structurel vers l’écosystème Anthropic
La limite la plus évidente tient à la source des données d’usage : elles proviennent exclusivement de Claude et de l’Anthropic Economic Index. Or, le marché des LLM est fragmenté. ChatGPT d’OpenAI, Gemini de Google, les modèles de Mistral AI, les LLM open source déployés en interne par certaines entreprises, rien de tout cela n’est capturé.
L’exposition « observée » est donc en réalité une exposition observée sur Claude, ce qui pourrait sous-estimer significativement la couverture réelle de certains métiers, notamment dans des secteurs où d’autres outils dominent (santé, droit, éducation). Les auteurs en sont conscients et mentionnent vouloir incorporer d’autres sources à l’avenir, mais cette limitation reste fondamentale pour l’interprétation des résultats, qu’il faut prendre avec précaution. Toutefois, la démarche méthodologique est vraiment pertinente et doit être saluée !
La frontière floue entre automatisation et augmentation
Le rapport propose de pondérer plus fortement les usages automatisés (via API) que les usages augmentatifs (conversation humain-IA). C’est une intuition raisonnable, mais la frontière entre les deux est plus poreuse qu’il n’y paraît. Un développeur qui utilise Claude Code pour écrire du code est-il « augmenté » ou « partiellement automatisé » ? Un service client qui intègre Claude en première ligne avec escalade humaine relève-t-il de l’automatisation complète ?
Le coefficient de pondération (plein poids pour l’automatisation, demi-poids pour l’augmentation) est un choix qui peut modifier sensiblement les résultats, et le rapport reconnaît que ces jugements sont en partie arbitraires…
L’angle mort de la création d’emplois
Le cadre analytique est entièrement centré sur le risque de déplacement : quels métiers verront leurs tâches automatisées ? C’est légitime, mais cela occulte la moitié de l’équation économique. L’histoire des technologies montre que les révolutions productives créent aussi des emplois (coucou Philippe Aghion) souvent dans des catégories qui n’existaient pas auparavant.
Les prompt engineers, les spécialistes de la gouvernance IA, les designers d’expériences conversationnelles, les formateurs à l’IA sont autant de fonctions émergentes que ce cadre ne capte pas. Un suivi de l’emploi dans les métiers créés par l’IA serait un complément indispensable à mettre « en face » de cette analyse.
Le chômage comme indicateur privilégié : un choix discutable
Les auteurs justifient leur focalisation sur le chômage par le fait qu’il capture directement le « préjudice économique ». C’est vrai, mais le chômage est aussi un indicateur tardif et imparfait. Un travailleur dont le métier est progressivement érodé peut connaître une baisse de salaire, une réduction de ses heures, un déclassement vers un emploi moins qualifié, ou une sortie de la population active, autant de phénomènes invisibles dans le taux de chômage… et ce d’autant plus que selon les marchés (en France par exemple), l’inertie joue à plein ! L’analyse des revenus, de la qualité de l’emploi et des transitions professionnelles apporterait une image bien plus complète et en tout cas complémentaire.
Une temporalité encore trop courte
Le rapport analyse la période post-ChatGPT (fin 2022 à début 2026), soit environ trois ans. C’est insuffisant pour observer des transformations structurelles du marché du travail. Comme les auteurs le notent eux-mêmes en comparant l’IA à l’internet ou au choc commercial chinois, les effets peuvent mettre une décennie à se matérialiser pleinement.
L’absence d’effet mesurable aujourd’hui ne préjuge en fait pas du tout de l’ampleur des transformations à venir, surtout si les capacités des modèles continuent de progresser au rythme actuel. De la même manière la présence d’effets important pourrait être stabilisée dans le futur. C’est le principe même de la transformation numérique : une position d’équilibre (possiblement très) différente du point de départ (mais équilibre quand même).
L’absence de dimension géographique et sectorielle
Le rapport raisonne au niveau des occupations agrégées sur l’ensemble des États-Unis. Or, l’exposition à l’IA est probablement très hétérogène selon les pays (avec un droit du travail qui diffère), les régions (les hubs technologiques versus les zones rurales), les tailles d’entreprise (les grandes entreprises adoptent plus vite) et les secteurs (la finance intègre l’IA plus rapidement que l’artisanat). Une désagrégation géographique et sectorielle renforcerait considérablement la portée des conclusions.
A ce titre, le rapport est entièrement centré sur les États-Unis. Les structures d’emploi, les réglementations du travail, les conventions collectives et les filets de sécurité sociale diffèrent profondément en Europe et en France en particulier. Les métiers identifiés comme les plus exposés (service client, saisie de données, programmation) existent aussi chez nous, mais dans des cadres institutionnels qui peuvent accélérer ou freiner les effets de l’IA. Une transposition directe des résultats serait imprudente. A ne pas faire donc !
Trois actions concrètes pour l’enseignement supérieur et la recherche en France
Ce rapport d’Anthropic, malgré ses limites, envoie un message clair : la transformation est engagée, elle touche prioritairement les emplois qualifiés et cognitifs, et les jeunes entrants sur le marché du travail semblent être les premiers affectés. Pour l’enseignement supérieur et la recherche (ESR) français, c’est un appel à l’action. Voici trois pistes concrètes qui me semblent plus que j’amais d’actualité.
Pour l’enseignement supérieur français, le message est clair : le temps de l’observation passive est terminé. Les établissements qui ont engagé dès 2023 une stratégie systémique d’intégration de l’IA de la formation des étudiants à celle des enseignants, des partenariats industriels à la recherche appliquée sont les mieux positionnés pour accompagner cette transformation. Les autres doivent accélérer, car la fenêtre pour préparer nos étudiants au monde qui vient se réduit chaque jour.
Action 1: Intégrer systématiquement l’IA dans tous les cursus, pas seulement les filières tech
Le rapport montre que les métiers les plus exposés ne sont pas uniquement ceux de l’informatique : analystes financiers, spécialistes marketing, représentants commerciaux, spécialistes des dossiers médicaux sont tous dans le top 10. Cela signifie que chaque programme de formation, en gestion, en droit, en santé, en sciences humaines, doit intégrer une formation opérationnelle à l’IA et une compréhension critique de ses impacts.
NEOMA Business School a fait figure de pionnière sur ce terrain. Dès septembre 2023, l’école a déployé un dispositif d’acculturation à l’IA générative à 360°, couvrant ses 10 000 étudiants, l’ensemble de sa faculté et ses collaborateurs, un effort reconnu par l’AACSB qui l’a sélectionné parmi les 26 innovations majeures mondiales dans l’éducation en 2024, faisant de NEOMA l’école européenne la plus primée par cet organisme. Depuis, plus de 12 000 personnes ont été formées, des tuteurs IA (jumeaux numériques des enseignants) ont été développés, un certificat exécutif Gen AI for Business et un MSc Artificial Intelligence for Business ont été lancés. Le partenariat stratégique signé avec Mistral AI en avril 2025, ouvrant l’accès aux outils de la licorne française à plus de 3 000 membres de la communauté, illustre une approche « Test & Learn » qui devrait, je crois, inspirer l’ensemble du secteur.
Cette dynamique doit essaimer au-delà des écoles de commerce pionnières. La démarche de l’Université de Rennes, l’alliance élargie avec Mistral AI et EdTech France rejointe par l’Institut Mines-Télécom, constituent des premières briques d’une mutualisation indispensable et que je continue d’appeler de mes voeux en multipliant les initiatives de partage. L’enjeu est maintenant de toucher les universités publiques, les IUT, les écoles d’ingénieurs et les formations paramédicales, bref, les filières qui forment les travailleurs identifiés comme exposés dans le rapport d’Anthropic.
Action 2 : Créer un observatoire français de l’exposition des métiers à l’IA
Le rapport d’Anthropic s’appuie sur O*NET (base américaine), le Current Population Survey (enquête américaine) et les projections du BLS (bureau statistique américain). Nous n’avons pas d’équivalent structuré en France. France Travail (ex-Pôle Emploi), la DARES et l’INSEE disposent de données riches mais pas encore organisées pour mesurer l’exposition des métiers à l’IA selon la méthodologie proposée par Anthropic.
L’enseignement supérieur et la recherche a un rôle naturel à jouer ici. Les laboratoires d’économie du travail, les chaires sur la transformation numérique, et les partenariats avec les acteurs de l’IA (Mistral AI, mais aussi les plateformes d’emploi comme Indeed ou LinkedIn) pourraient alimenter un observatoire français croisant les données de capacité théorique, d’usage réel et d’évolution de l’emploi. Cet observatoire permettrait de fonder les politiques publiques de formation et de reconversion sur des données probantes plutôt que sur des intuitions.
Action 3 : Repenser l’insertion professionnelle des jeunes diplômés à l’aune de l’IA
Le signal le plus préoccupant du rapport concerne les 22-25 ans : un ralentissement de 14 % de leur taux d’entrée dans les métiers exposés. Si cette tendance se confirme, elle pose une question existentielle à l’enseignement supérieur : formons-nous nos étudiants pour des postes d’entrée qui n’existeront plus sous leur forme actuelle ?
La réponse ne peut pas être uniquement défensive (former à l’IA pour « rester compétitif »). Elle doit être offensive : former des diplômés capables de redéfinir leur propre poste, d’identifier où l’IA crée de la valeur et où l’humain reste irremplaçable, de piloter des projets de transformation. Cela passe par des pédagogies expérientielles, ce que NEOMA expérimente avec ses simulateurs d’IA et ses projets en conditions réelles (depuis près d’une décennie maintenant).
Concrètement, trois leviers sont à activer. Le premier est l’adaptation des stages et de l’alternance : les établissements doivent travailler avec leurs entreprises partenaires pour que les missions confiées aux étudiants intègrent explicitement l’IA, non pas comme un sujet d’étude mais comme un outil de travail quotidien. Le deuxième est le suivi longitudinal des diplômés : les enquêtes d’insertion (à 6 mois, 1 an, 3 ans) doivent désormais mesurer l’exposition à l’IA du poste occupé, les compétences mobilisées et les transitions opérées. Le troisième est la formation continue : comme le montrent le Certificat Executive « Generative AI for Business » de NEOMA et sa déclinaison grand public sur NEOMA Online, l’acculturation à l’IA ne peut pas s’arrêter au diplôme initial. Les alumni des grandes écoles et universités sont le premier public à accompagner dans cette transformation, car ce sont eux qui occupent aujourd’hui les postes identifiés comme les plus exposés par le rapport d’Anthropic.
Conclusion
Le rapport d’Anthropic a le mérite de poser un cadre méthodologique solide, fondé sur des données d’usage réel plutôt que sur des projections spéculatives. Sa conclusion principale : pas de catastrophe sur l’emploi à ce stade, mais des signaux précoces de transformation, notamment pour les jeunes est à la fois rassurante et alertante.
Références :
Massenkoff, M. & McCrory, P. (2026). Labor market impacts of AI: A new measure and early evidence. Anthropic. Disponible sur : anthropic.com/research/labor-market-impacts
Annexes du rapport : appendix.pdf


