 par
par Introduction : 2025 une année structurante en IA
L’année 2025 marque un tournant pour l’intelligence artificielle (IA). Jamais une technologie ne s’était diffusée aussi vite ni n’avait suscité autant d’investissements en si peu de temps. Le rapport “Trends – Artificial Intelligence” publié en mai 2025 par le fonds BOND (mené par la célèbre analyste Mary Meeker) dresse un panorama riche de données sur cette révolution en cours. On y découvre une adoption utilisateur sans précédent, une croissance exponentielle des usages, une explosion du CapEx (dépenses d’investissement technologique) liée à l’IA, des progrès rapides des modèles d’IA (jusqu’à approcher le rêve d’une IA générale), l’émergence d’agents autonomes, mais aussi de profondes transformations du travail et une véritable course géopolitique pour le leadership de l’IA.
Cet article propose une synthèse analytique de ces tendances clés, enrichie des développements survenus depuis la publication du rapport (nouvelles versions de modèles comme GPT-5, Gemini 2/2.5, Claude 3.5+, annonces politiques récentes, percées en robotique, etc.). Nous expliquerons les concepts techniques de manière pédagogique (LLM, CapEx, AGI, agents…) et mettrons en perspective les implications sociétales et économiques majeures : transformation des emplois, défis pour l’éducation, nouvelles interfaces homme-machine. Enfin, nous n’éluderons pas les risques associés (biais, concentration du pouvoir, dépendance technologique…), avant de conclure sur une réflexion ouverte : que pourrait être l’IA en 2030 ?
Adoption exponentielle : l’IA bat tous les records
L’essor de l’IA actuelle – en particulier de l’IA générative – se caractérise par une rapidité d’adoption inédite. Aux États-Unis, il n’a fallu qu’environ 3 ans pour que l’IA atteigne 50% de taux d’adoption dans la population, là où l’internet mobile en avait mis 6, l’internet fixe 12 et le PC 20. Autrement dit, la courbe d’adoption de l’IA surpasse de loin celle de toutes les révolutions technologiques précédentes.

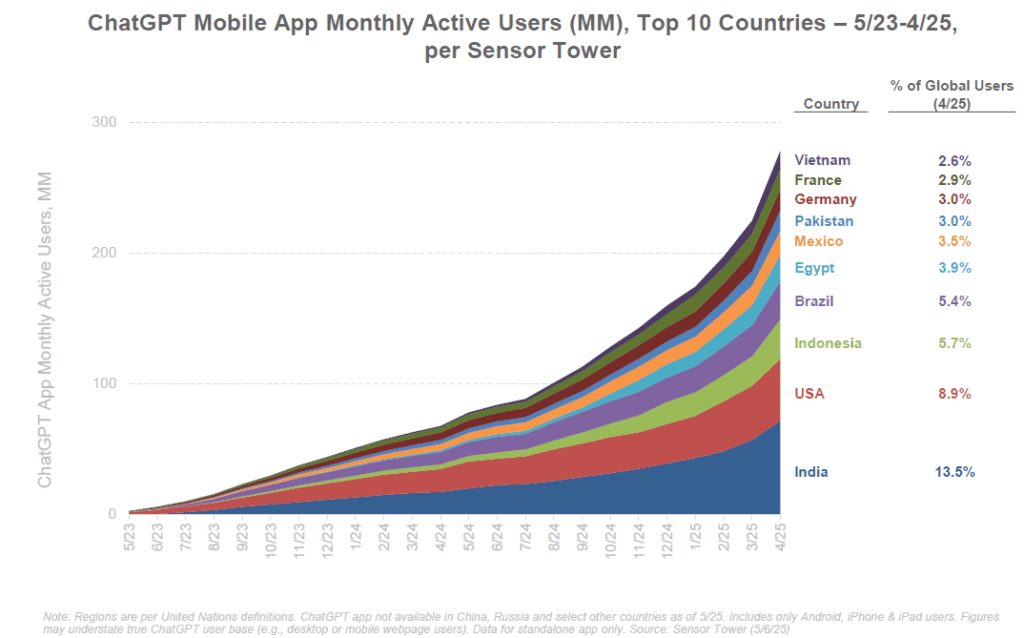
ChatGPT, l’agent conversationnel d’OpenAI, illustre cette dynamique fulgurante. Lancé fin 2022, il a atteint 1 million d’utilisateurs en 5 jours seulement (quand il avait fallu ~10 ans à la Ford Model T pour écouler le million d’unités). Mieux, ChatGPT a franchi le cap des 100 millions d’utilisateurs en à peine 2 mois, pulvérisant le record de TikTok (9 mois) et d’Instagram (30 mois). Au bout de 17 mois, fin avril 2025, ChatGPT revendiquait déjà 800 millions d’utilisateurs – soit environ 10% de la population mondiale – un rythme de croissance qualifié d’« sans précédent dans l’histoire tech ». Pour comparaison, Netflix n’a atteint les 100 millions d’abonnés qu’en une décennie. L’adoption globale est également notable : dès sa troisième année, environ 90% des utilisateurs de ChatGPT étaient en dehors d’Amérique du Nord, là où il avait fallu 23 ans à l’Internet pour se mondialiser autant.
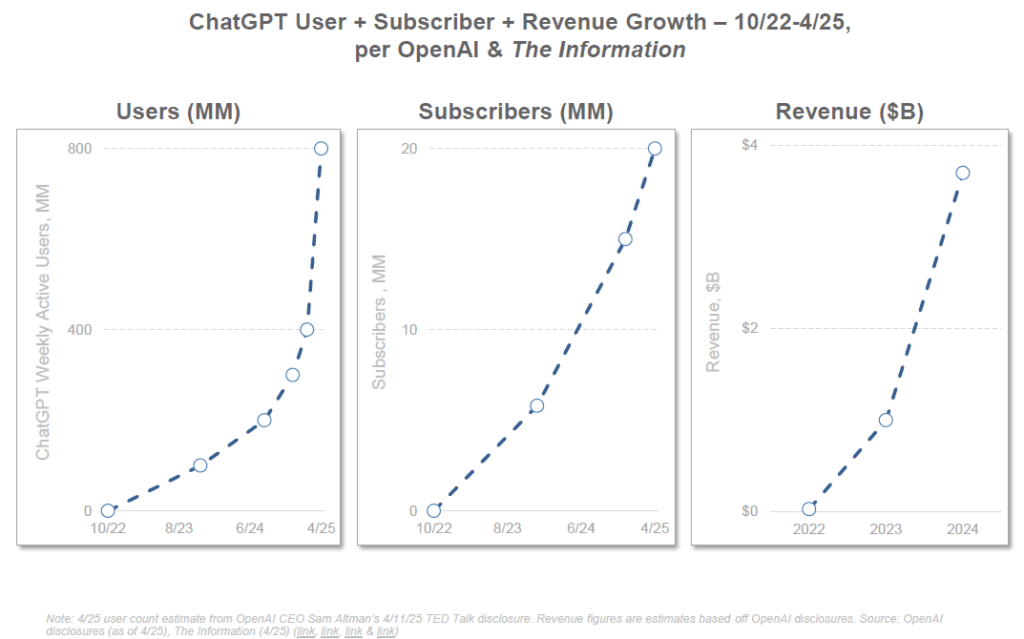
Les usages eux aussi explosent. ChatGPT a enregistré 365 milliards de requêtes annuelles dès sa deuxième année d’existence (2024), un volume de requêtes qu’il avait fallu 11 ans à Google pour atteindre. De plus, l’engagement des usagers s’intensifie : aux États-Unis, le temps quotidien moyen passé sur ChatGPT a augmenté de +202% en 21 mois, dépassant les 20 minutes par jour, et le taux de rétention est exceptionnel (80% des utilisateurs reviennent régulièrement, contre ~58% pour la recherche Google). En entreprise, on observe un engouement similaire : près de 50% des sociétés du S&P 500 évoquent désormais l’IA dans leurs communications financières, alors qu’elles étaient quasi nulles à le faire en 2015. Plusieurs applications grand public basées sur l’IA ont atteint des millions d’utilisateurs en quelques jours ou semaines. L’IA s’insinue dans de nombreux produits existants : les géants du numérique (Google, Meta, Apple, Microsoft…) intègrent désormais des fonctions d’IA générative dans des services utilisés par des milliards de personnes (recherche en langage naturel, assistants intelligents, génération d’images, etc.).
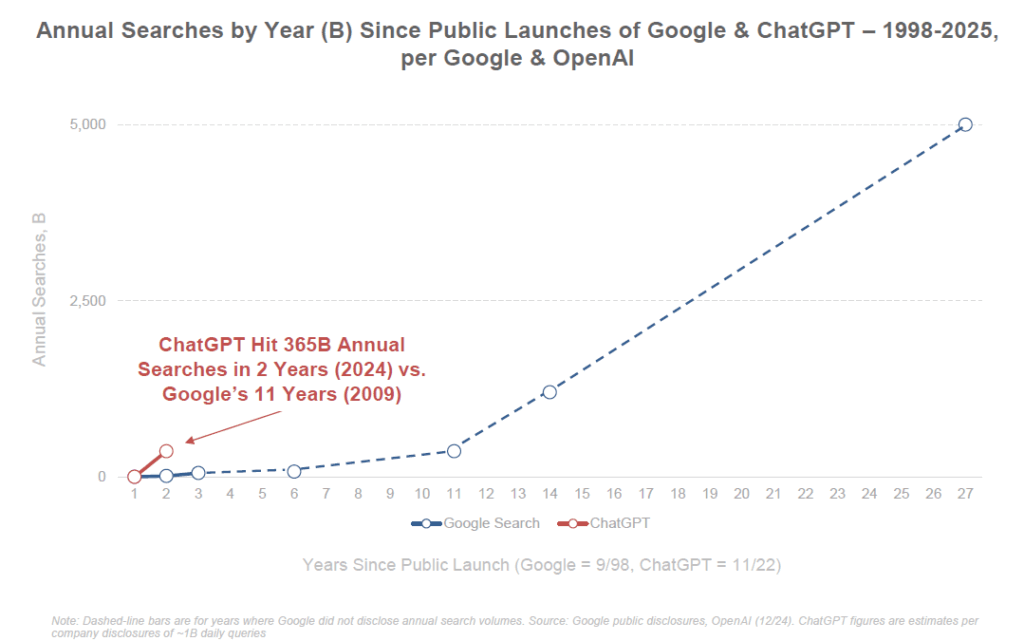
En somme, la diffusion de l’IA est exponentielle. Le rapport de BOND souligne que « la courbe d’adoption des plateformes d’IA est sans équivalent », confirmant l’impression de beaucoup d’observateurs que cette révolution technologique est plus rapide et globale que les précédentes.
Course à la puissance : des investissements colossaux et des progrès techniques fulgurants
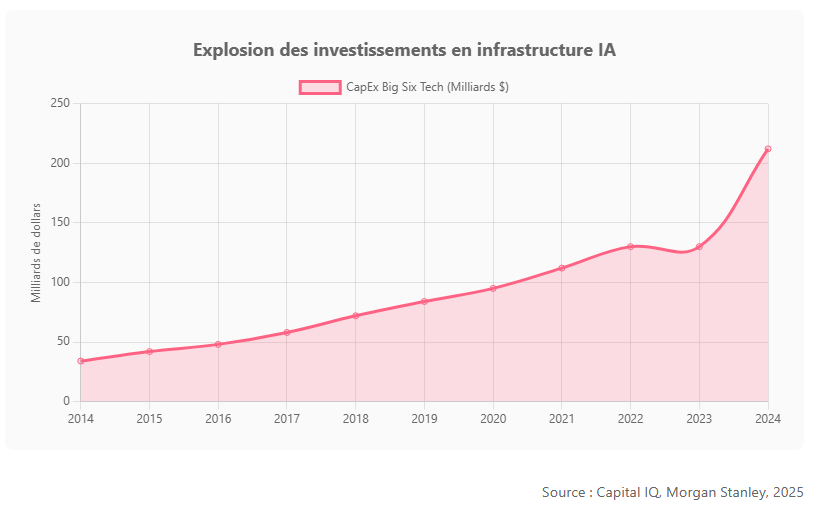
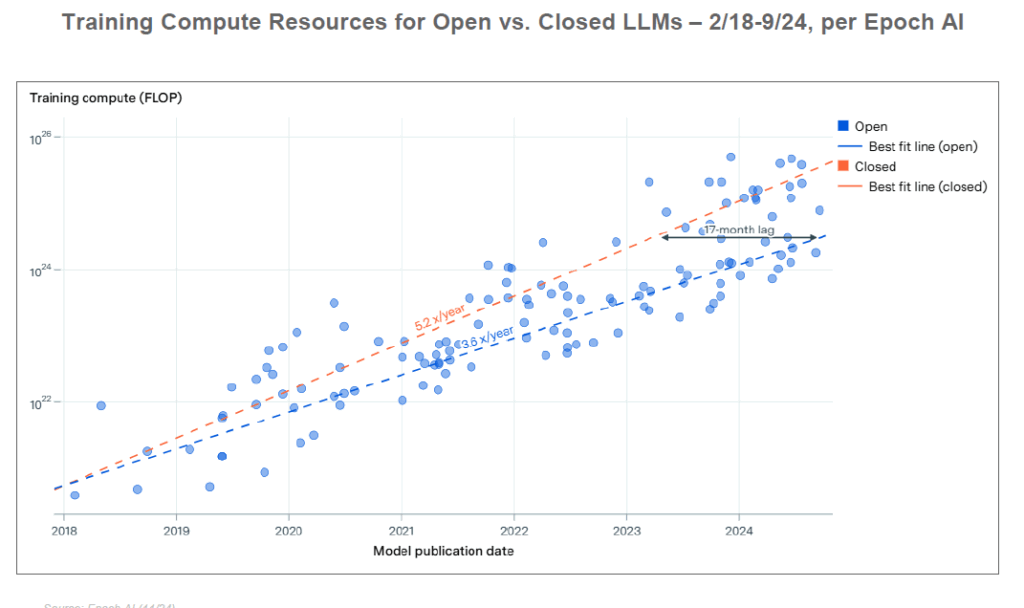
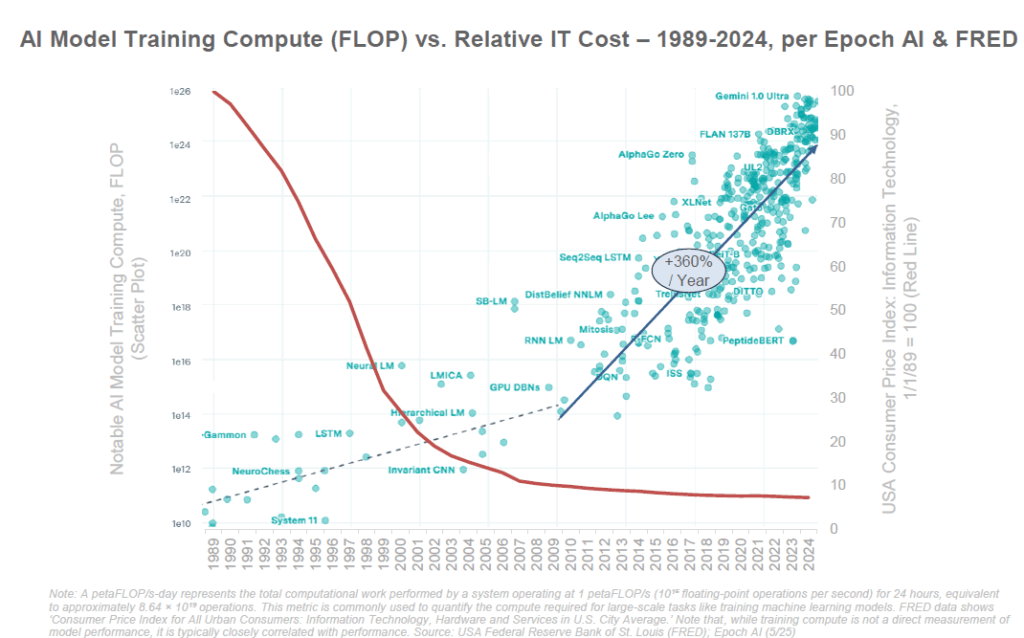
Pour soutenir cette croissance, les investissements technologiques liés à l’IA connaissent une explosion sans précédent. Les grandes entreprises technologiques ont considérablement accru leurs dépenses d’infrastructure (CapEx : capital expenditure, c’est-à-dire les dépenses d’investissement en capital, par exemple dans les centres de données, serveurs, puces spécialisées, etc.). Sur la dernière décennie, le CapEx des six plus grandes firmes tech a cru d’environ 21% par an pour atteindre 212 milliards $, et a même bondi de +63% sur la seule année 2024 sous l’effet de la ruée vers l’IA. Cela signifie qu’en 2024 ces entreprises ont investi une part record de leurs revenus (15%, contre 8% en 2014) dans les infrastructures technologiques, notamment l’IA. Amazon Web Services (AWS) a par exemple consacré près de 49% de son chiffre d’affaires 2024 à ses dépenses d’infrastructure cloud et IA, dépassant largement le pic (~27%) de l’époque de la construction des premiers clouds.
Cette frénésie d’investissement s’explique par les besoins massifs en calcul de l’IA moderne. En effet, entraîner les modèles IA les plus avancés coûte extrêmement cher : on estime que la création de GPT-4 a nécessité des dizaines de millions de dollars en puissance de calcul. Le rapport note que les coûts d’entraînement ont explosé d’un facteur ×2 400 en 8 ans, avec la perspective de modèles coûtant jusqu’à 10 milliards $ à entraîner d’ici 2025 selon certains experts. Former et déployer ces IA nécessite des data centers entiers truffés de puces spécialisées (GPU, TPU, etc.). D’après les projections de McKinsey, satisfaire la demande mondiale en puissance de calcul pour l’IA pourrait exiger plus de 5 200 milliards $ d’investissements cumulés d’ici 2030 (sur un total d’environ 7 000 Mds$ en incluant les besoins informatiques hors-IA). Autrement dit, l’IA représente désormais la majeure partie de la croissance des dépenses d’infrastructure informatique. En 2024, les investissements mondiaux dans les centres de données ont d’ailleurs atteint un record, de l’ordre de 455 milliards $, portés par la vague de l’IA. Ces centres deviennent de véritables « usines à IA », construites à un rythme accéléré (certains “hyperscalers” érigent des méga-centres en quelques mois).
Un exemple frappant : la startup xAI (lancée par Elon Musk en 2023) a bâti en un temps record un centre de calcul de 70 000 m², nommé “Colossus”, sorti de terre en 122 jours seulement, et a déployé 200 000 GPU en 7 mois – avec l’ambition d’atteindre 1 million de GPU à court terme. Cette course à l’armement technologique illustre la féroce compétition en cours pour disposer de la capacité de calcul nécessaire à l’IA de pointe.
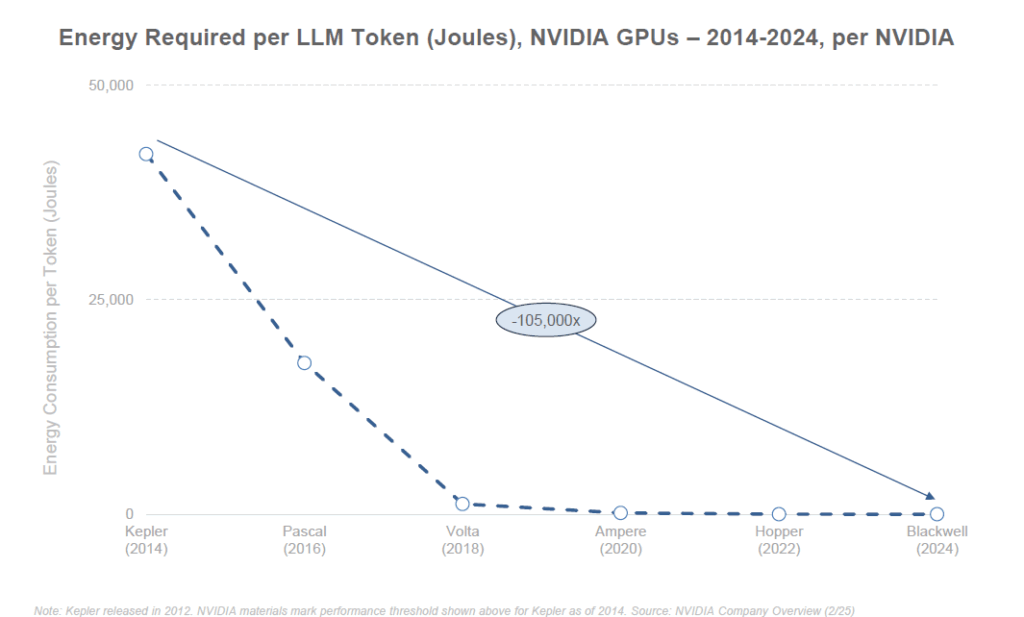
Parallèlement aux dépenses, les performances techniques progressent à un rythme exponentiel. La loi de Moore (doublement de la puissance des puces tous les 2 ans) paraît modeste face aux gains constatés en IA. Par exemple, NVIDIA, principal fournisseur de processeurs pour l’IA, a vu la puissance de calcul de ses GPU déployée globalement être multipliée par ×100 en 6 ans (+130% par an). Un seul GPU de dernière génération (architecture Blackwell prévue en 2024) permet de traiter une requête d’IA avec 105 000 fois moins d’énergie qu’un GPU de 2014 – signe d’une efficacité énergétique et d’une performance en croissance vertigineuse. Globalement, la performance des supercalculateurs spécialisés en IA a augmenté d’environ 150% par an ces dernières années, tirée par l’augmentation du nombre de puces par cluster et les progrès de chaque puce. Le résultat concret, c’est que les modèles d’IA peuvent être entraînés plus rapidement et pour moins cher qu’avant (même si, comme on l’a vu, le seuil de pointe ne cesse de grimper pour battre l’état de l’art).
En parallèle, le coût d’utilisation de l’IA baisse drastiquement grâce aux gains d’efficacité. Le coût d’inférence (faire tourner le modèle pour répondre aux questions) a ainsi diminué de 99% en deux ans (coût par million de tokens). Autrement dit, fournir des réponses d’IA est de moins en moins cher, ce qui facilite son intégration dans toutes sortes d’applications et fait baisser les prix pour les utilisateurs finaux. Cette baisse des coûts d’utilisation, couplée à l’intense concurrence, conduit à une démocratisation de l’IA dans les produits : de nombreux services offrent aujourd’hui des fonctionnalités IA gratuites ou peu chères, accélérant encore l’adoption.

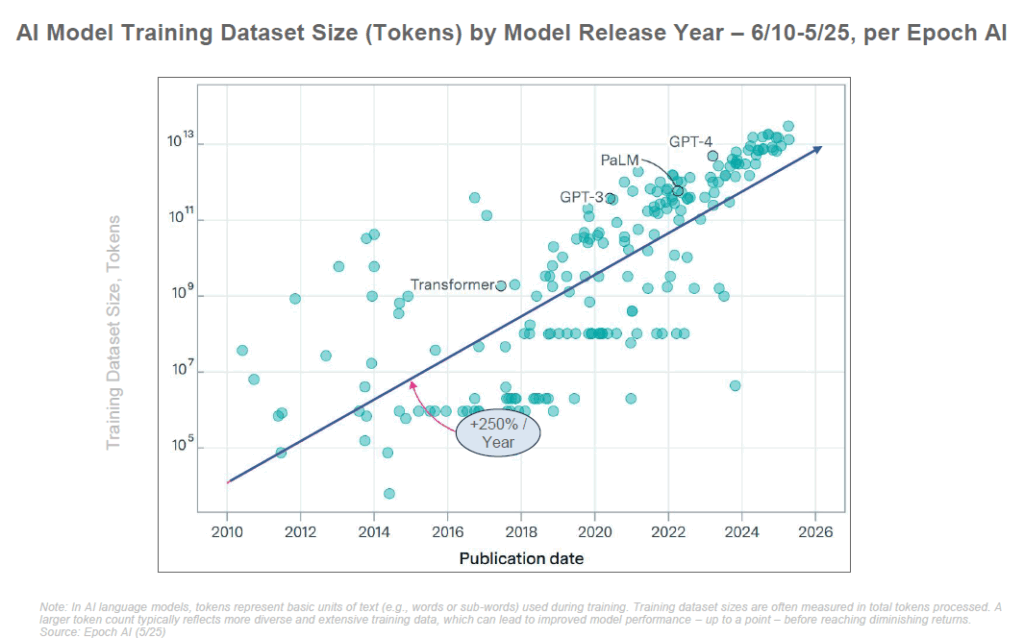
On assiste également à une explosion du nombre de modèles IA disponibles. Le rapport de BOND note une croissance de +167% par an depuis 2020 du nombre de modèles d’IA « puissants » publiés. Rien qu’entre 2022 et 2024, le nombre de grands modèles de langage (LLM, comme GPT) a été multiplié par plus de 5 (×5,2), et le nombre de modèles d’IA « à grande échelle » (incluant vision, multimodal, etc.) par 12,5 (×12,5).
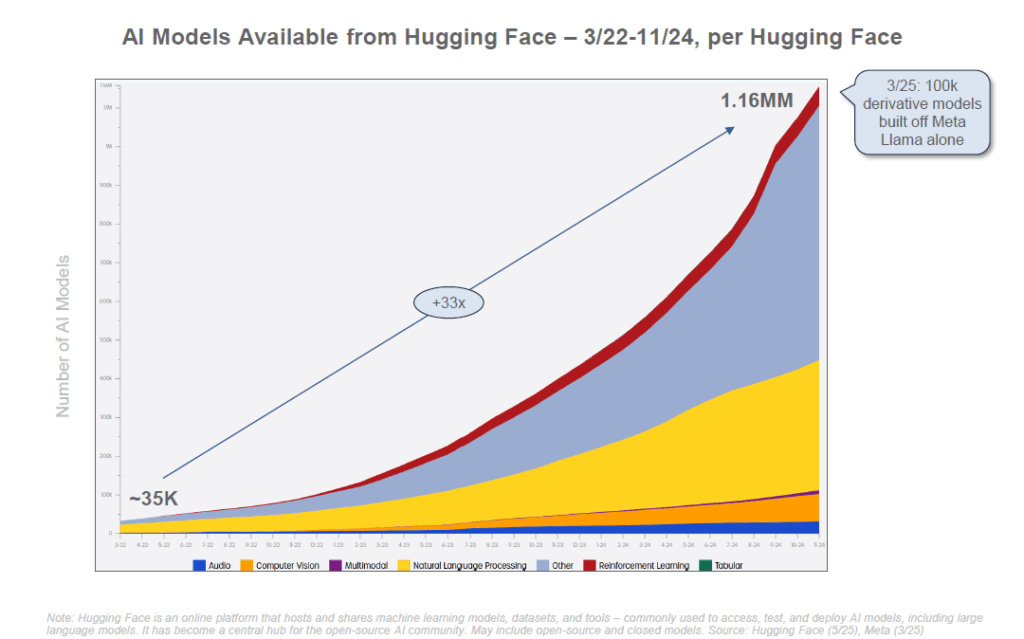
Cette prolifération s’explique notamment par l’essor de l’open source : des modèles initialement développés par des laboratoires de recherche ou des entreprises ont vu leurs poids publiés (comme le modèle LLaMA de Meta), permettant à la communauté de les améliorer, les adapter et de créer de nouvelles versions.
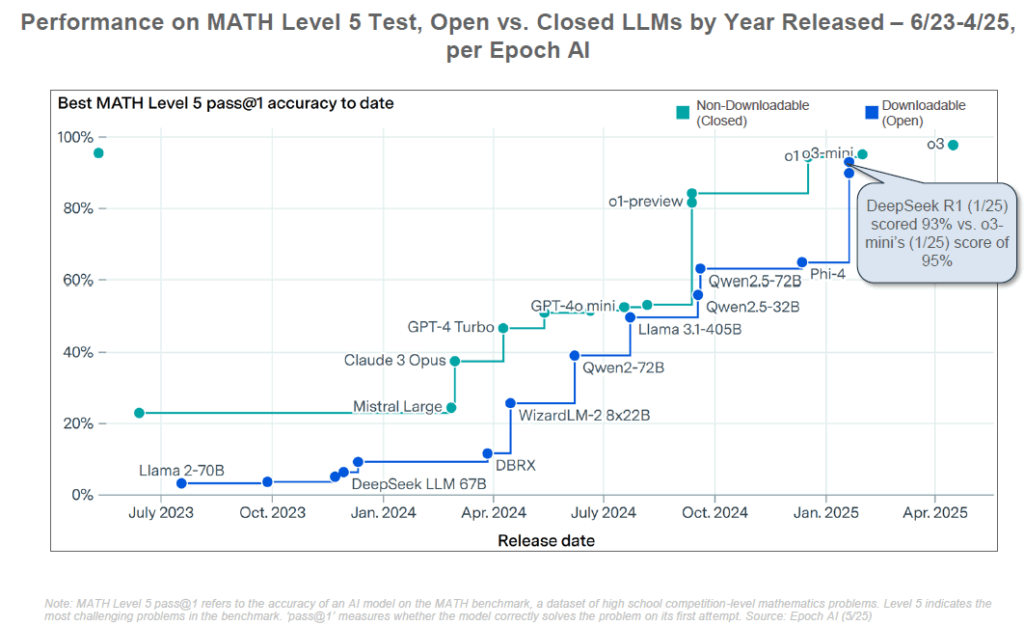
En effet, deux philosophies s’opposent désormais dans le paysage de l’IA : les approches fermées (closed source, menées par les géants privés qui entraînent des modèles propriétaires très coûteux, type GPT-4 ou Claude) et les approches ouvertes (open source, avec des modèles dont les paramètres sont publiés, permettant à n’importe qui de les utiliser et les affiner). Les modèles fermés dominent aujourd’hui le marché en termes de performance brute et d’adoption commerciale (prisés par les entreprises pour leur facilité d’utilisation et leur efficacité), mais ils soulèvent des critiques par leur opacité. À l’inverse, les modèles ouverts – souvent moins performants à l’origine – ont l’avantage de la transparence et d’un coût bien moindre, ce qui démocratise l’accès à l’IA de pointe (pour des startups, des chercheurs ou des gouvernements disposant de budgets limités). BOND souligne que la Chine a particulièrement misé sur l’open source : au deuxième trimestre 2025, la Chine est leader en nombre de grands modèles IA open source publiés, avec déjà trois modèles majeurs annoncés en 2025 (dont DeepSeek-R1, Alibaba Qwen-32B et Baidu Ernie 4.5). La philosophie open source y est encouragée pour stimuler l’innovation locale et contourner la dépendance aux géants américains. Pendant ce temps, du côté fermé, les acteurs en place rivalisent d’investissements : comme le résume Mary Meeker, « ces paris ne sont pas des projets secondaires – ce sont des paris fondateurs » pour l’avenir des entreprises.
Des modèles toujours plus performants (GPT-4, GPT-5, Claude, Gemini…)
Le progrès rapide des modèles d’IA eux-mêmes est un moteur central de cette révolution. Depuis le lancement de GPT-3 en 2020, chaque nouvelle génération de Large Language Model (LLM) repousse les limites de ce que l’IA peut accomplir. GPT-4 (OpenAI, 2023) a impressionné en réussissant des examens humains difficiles (barreau, concours d’ingénieur…) et en approchant ou dépassant le niveau humain sur de nombreux tests académiques. Par exemple, sur le benchmark MMLU (qui évalue des connaissances de niveau universitaire), un système d’IA de pointe atteint désormais 92,3% de réussite, dépassant la moyenne humaine (89,8%). Cette performance autrefois inimaginable alimente les espoirs d’IA générale (AGI, Artificial General Intelligence), c’est-à-dire une IA capable d’égaler l’être humain dans toutes ses tâches intellectuelles.
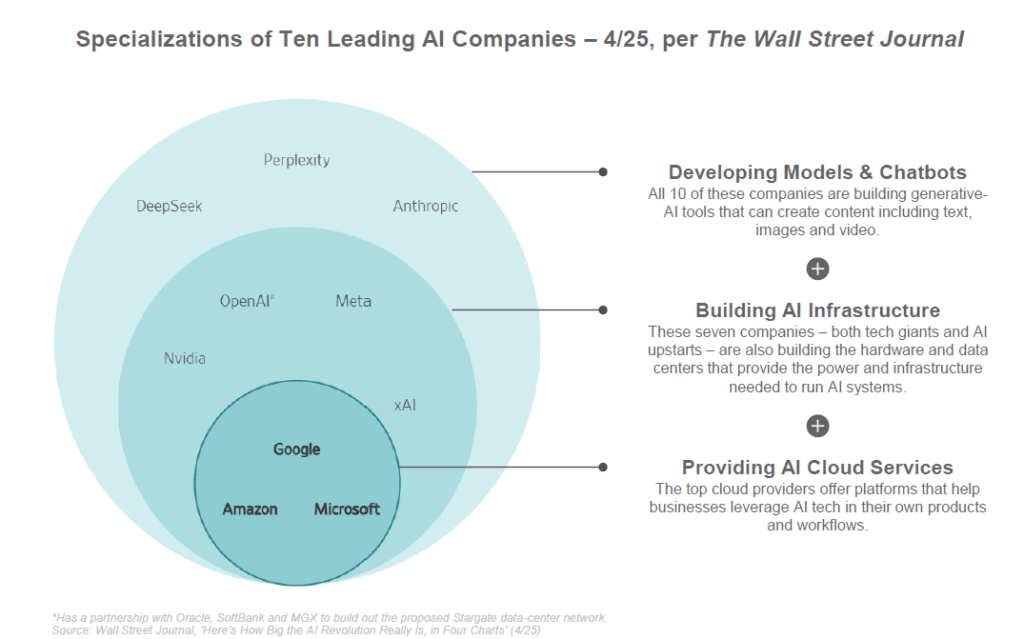
OpenAI, leader du domaine, poursuit sa feuille de route agressive. Après GPT-4, une version intermédiaire nommée GPT-4.5 (« Orion ») serait sortie en version API début 2025, suivie d’améliorations graduelles (GPT-4.1…). Surtout, les rumeurs autour de GPT-5 vont bon train. Sam Altman (CEO d’OpenAI) a indiqué début 2025 qu’il faudrait encore “quelques mois” avant la sortie du modèle suivant, suggérant une possible annonce à l’été 2025. Plusieurs fuites laissent entendre que GPT-5 serait en test interne et surpasserait largement les précédents sur de nombreux critères. Ce modèle pourrait représenter un saut majeur vers l’AGI, avec des avancées attendues telles que : une véritable multimodalité (texte, images, voix gérés de façon unifiée), une mémoire à long terme lui permettant d’apprendre sur la durée, nettement moins d’hallucinations (grâce à des données d’entraînement enrichies et des optimisations d’architecture), et une architecture unifiée intégrant des capacités aujourd’hui séparées (code, vision, outils) en un seul agent intelligent. En somme, GPT-5 ambitionne d’être plus polyvalent, précis et intégré. S’il tient ses promesses, il pourrait inaugurer une nouvelle ère d’assistants AI encore plus utiles au quotidien, et OpenAI espère un impact transversal sur toutes les industries grâce à ces capacités accrues. Bien entendu, au moment de rédiger cet article (mi-2025), GPT-5 n’est pas confirmé officiellement, mais nombre d’observateurs parient sur un lancement dans les mois à venir.
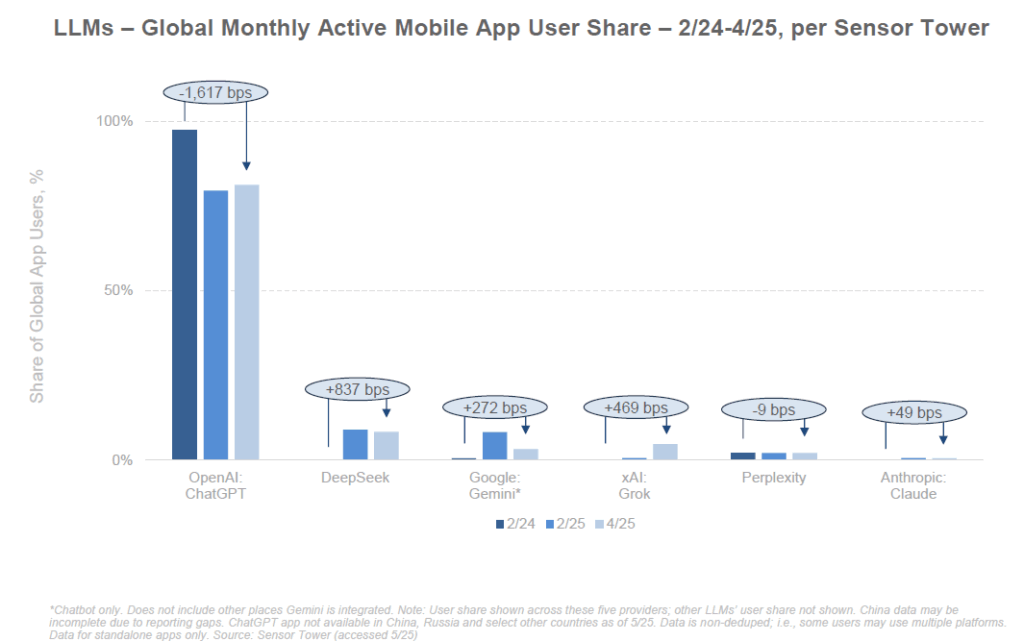
OpenAI n’est pas seul dans cette course aux modèles géants. Du côté de Google/DeepMind, l’effort s’est cristallisé autour du programme Gemini. Dévoilé comme un projet phare en 2023, Gemini a pour ambition de concurrencer GPT-4 en combinant techniques d’apprentissage et de planification issues de DeepMind (AlphaGo) avec la puissance des LLM. En 2024, Google a lancé PaLM 2 puis des premières versions de Gemini en avant-première. En 2025, la firme a présenté Gemini 2.0 puis Gemini 2.5 Pro, versions successives améliorant les performances. Par exemple, Gemini 2.5 Pro (mise en avant lors de Google I/O 2025) a revendiqué la première place sur plusieurs benchmarks, notamment en génération de code où il surpasserait les autres modèles connus. Demis Hassabis (CEO de DeepMind) a annoncé avec enthousiasme qu’il s’agissait du « meilleur modèle de codage jamais conçu », propulsant Google en tête sur des évaluations de programmation. Gemini 2.5 est accessible via l’API de Google Cloud (Vertex AI) et intégré dans Bard (le chatbot de Google), signe de la volonté de Google d’infuser ses produits de cette nouvelle intelligence. On peut s’attendre à ce que Gemini 3 soit dévoilé prochainement, Google ayant adopté un rythme de mises à jour fréquentes (la version 2.5 était déjà une amélioration substantielle sur la 2.0 initiale). L’objectif affiché est de rattraper puis dépasser GPT-4/GPT-5, notamment grâce à l’énorme base de données de Google et son expertise en ingénierie.
Anthropic, autre acteur majeur, poursuit également le développement de sa famille Claude. En février 2025, Anthropic a dévoilé Claude 3.7 “Sonnet”, son modèle le plus avancé à ce jour, surpassant le modèle Claude 3.5 “Haiku” précédent en combinant deux modes de réponse (instantané ou réfléchi). Claude 3.7 se distingue par une capacité de raisonnement pas à pas qu’on peut activer au besoin (l’IA « pense » quelques secondes à quelques minutes, améliorant la fiabilité des réponses complexes). Anthropic a opté pour des noms poétiques mais la progression suit une logique de versions : un Claude 4 (sûrement nommé “Opus” ou autre) est anticipé dans le courant 2025, visant à combler l’écart avec GPT-4/5. Des sources indiquent qu’une variante Claude 3.5 améliorée (Claude 3.5 « Sonnet ») a déjà été testée, surpassant même GPT-4 sur certaines tâches de raisonnement et de codage. Anthropic met l’accent sur la sûreté et le contrôle des réponses, se positionnant comme une alternative “plus prévisible et moins biaisée” que GPT pour les entreprises.
Enfin, Meta (maison-mère de Facebook) joue la carte de l’open source : après le succès de LLaMA 2 (un grand modèle de langage open source de 70 milliards de paramètres publié en 2023), on attend une éventuelle LLaMA 3 en 2024-2025. Meta parie que la communauté des développeurs peut itérer plus vite sur des modèles ouverts, et préfère distribuer la puissance plutôt que de courir à l’énorme modèle propriétaire. Cette stratégie a été payante en termes d’adoption par les chercheurs et innovateurs indépendants (LLaMA a servi de base à d’innombrables projets). D’autres acteurs notables incluent IBM (avec sa série Granite et modèles spécialisés entreprise), Huawei en Chine, et diverses startups innovantes qui, via l’open source ou des approches spécialisées, contribuent à l’enrichissement de l’écosystème de modèles.
En résumé, les modèles d’IA progressent à une vitesse inégalée, soutenus par des investissements massifs et une compétition mondiale. Chaque nouvelle génération élargit le champ des possibles (par ex., la génération d’images ultra-réalistes, la compréhension audio/vidéo, la résolution de problèmes scientifiques, etc.). À ce rythme, la barre de l’intelligence artificielle générale (AGI) – longtemps reléguée à la science-fiction – semble se rapprocher. Sam Altman a même déclaré publiquement en 2023 : « Nous savons désormais comment construire une AGI », reflétant l’optimisme (ou l’audace) de certains pionniers. Reste à transformer ces promesses en réalités fiables et bénéfiques.
L’émergence des agents autonomes : vers des IA qui agissent
Jusqu’à récemment, la plupart des IA génératives étaient essentiellement réactives : elles répondaient à des requêtes humaines sans initiative propre. Désormais se profile l’ère des agents autonomes, des IA capables non seulement de converser, mais aussi de planifier et d’exécuter des tâches de manière proactive, avec un minimum d’intervention humaine. Le rapport BOND souligne cette évolution « du chatbot à l’agent » (de « simples réponses » à « l’exécution de travaux »). En d’autres termes, l’IA ne se contente plus de fournir de l’information : on lui assigne un objectif et elle peut aller chercher les moyens d’y parvenir, en enchaînant des actions diverses.
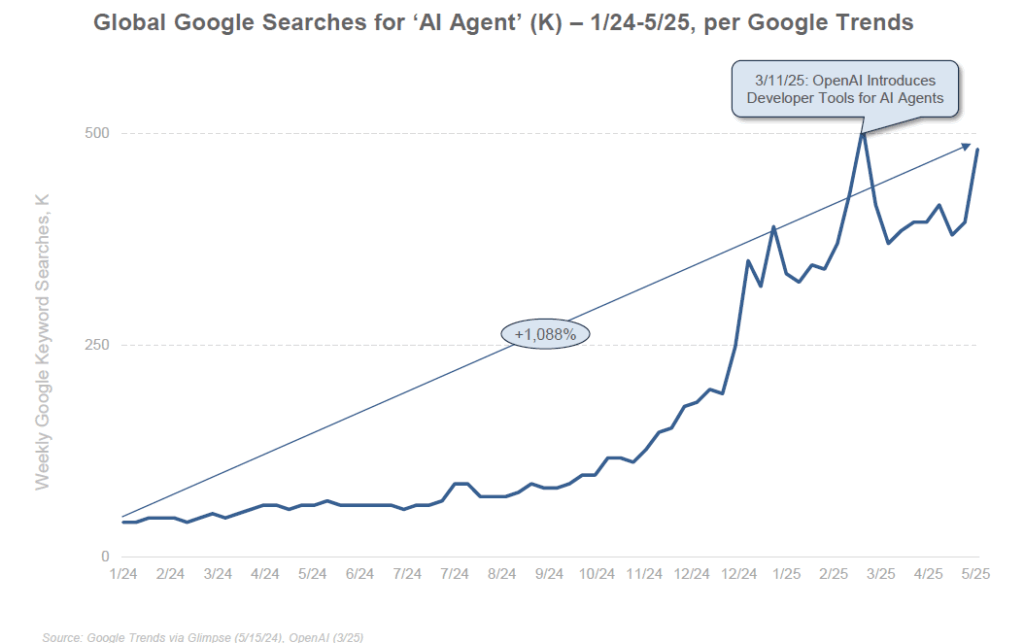
L’intérêt pour ces agents IA a littéralement explosé depuis 2023. Des projets expérimentaux comme AutoGPT, BabyAGI ou AgentGPT ont fait le buzz en donnant un aperçu de ce que pourrait être une IA « auto-entreprenante ». Ces programmes open source, basés sur GPT-4, permettaient de définir une mission générale et laissaient ensuite l’IA générer ses propres sous-objectifs, requêtes et actions en boucle pour tenter d’accomplir la mission. En quelques semaines au printemps 2023, le dépôt GitHub d’AutoGPT a recueilli plus de 100 000 étoiles, signe d’un engouement massif des développeurs. Ce concept d’“agentic AI” (IA agentique) a entraîné la création de dizaines de projets similaires et une explosion de discussions en ligne sur le potentiel – mais aussi les limites – de ces agents autonomes. Les recherches du mot-clé “AI agent” sur Google ont ainsi grimpé de +1088% en 16 mois fin 2024, illustrant l’attention grandissante du public et des professionnels.
Si beaucoup de ces premières implémentations se sont révélées encore maladroites ou limitées (répétitions d’actions, tendance à “s’emballer” sans supervision humaine, etc.), elles ont pavé la voie à l’intégration des agents dans des produits concrets. En 2024-2025, plusieurs plateformes majeures ont annoncé le déploiement de leurs propres agents IA : par exemple, Salesforce a présenté “Einstein GPT” puis “AgentGPT” dans son CRM pour automatiser certaines interactions clients, Anthropic a introduit la fonction “Computer Use” pour que son IA Claude puisse utiliser un ordinateur virtuel, et OpenAI travaillerait sur un agent évolué nommé “Operator”. Microsoft, de son côté, intègre de plus en plus de capacités agentiques dans son assistant Copilot (qui peut, dans Windows ou Office, enchaîner des actions à la voix de l’utilisateur pour accomplir une tâche complexe). On voit aussi émerger des agents spécialisés : des IA déployées pour gérer de façon autonome un aspect particulier, par exemple un assistant email qui triera et répondra automatiquement à votre courrier, un agent RH qui présélectionne des CV et planifie des entretiens, ou un agent développeur qui tente de corriger du code et déployer une application selon un cahier des charges minimal.
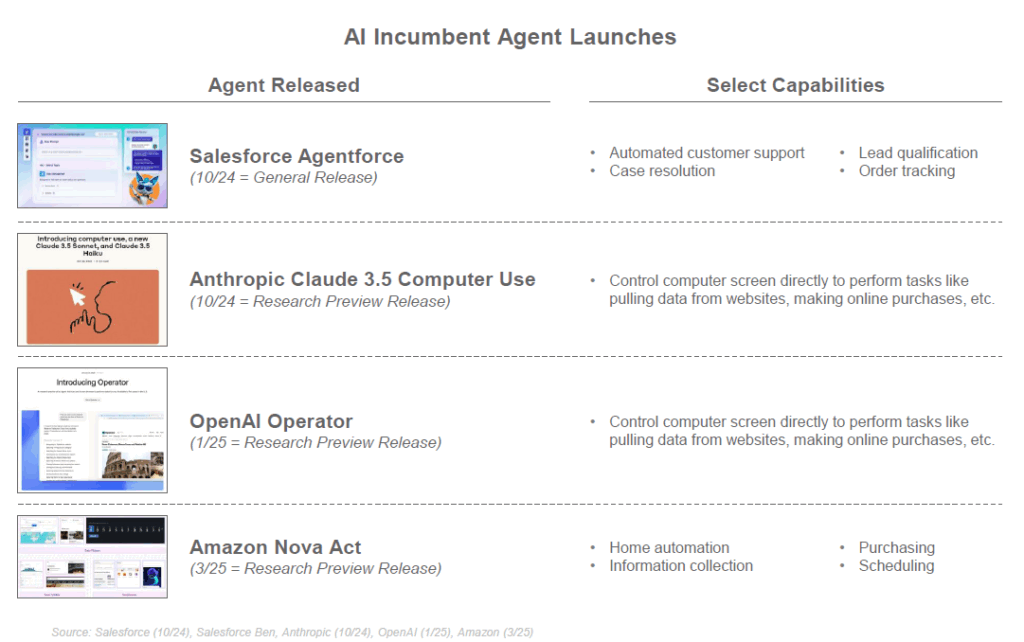
Cette évolution vers des IA qui agissent soulève autant d’enthousiasme que de questions. D’un côté, elle promet une automatisation avancée : on peut envisager déléguer à un agent le soin de “gérer un projet” à notre place, de la conception à l’exécution, avec une supervision humaine minimale. Cela pourrait révolutionner la productivité dans de nombreux domaines (assistants personnels ultra-proactifs, optimisation automatique de processus d’entreprise, etc.). Des gains de temps considérables sont espérés, l’agent pouvant travailler 24h/24 à résoudre un problème étape par étape.
D’un autre côté, ces agents posent des défis techniques et éthiques. Techniquement, leur fiabilité est un enjeu majeur : sans surveillance humaine, un agent peut se perdre dans des boucles d’actions non pertinentes, mal interpréter un objectif, ou causer des dégâts (imaginez un agent financier prenant des décisions d’investissement hasardeuses). La sécurité est cruciale : un agent ayant accès à des outils (ordinateur, internet, API diverses) doit être bridé pour ne pas effectuer d’actions dangereuses ou malveillantes. C’est tout l’objet de la recherche en AI safety appliquée aux agents : comment leur permettre d’être autonomes tout en restant alignés avec les intentions de leur opérateur et les valeurs humaines.
En 2025, on n’en est qu’aux prémices de ces agents autonomes grand public. Néanmoins, les progrès rapides en langage naturel, en planification algorithmique et en utilisation d’outils par l’IA (fonctionnalité dite des plugins ou outils intégrés où le LLM peut appeler des services externes comme un navigateur, un calendrier, etc.) convergent clairement vers cette direction. Il est probable que dans les prochaines années, nos “assistants virtuels” deviendront de vrais agents, pouvant gérer en notre nom des tâches complexes (prendre rendez-vous, réserver des voyages selon nos préférences, effectuer des démarches administratives, etc.), en se coordonnant avec d’autres IA si nécessaire.
En somme, l’émergence des agents autonomes annonce une nouvelle étape de l’IA : après la phase de l’IA qui voit (reconnaissance visuelle), qui lit (NLP) et qui parle (synthèse vocale), voici venir l’IA qui agit. Reste à encadrer cette autonomie naissante pour qu’elle serve au mieux nos intérêts et s’intègre harmonieusement dans nos environnements techniques, professionnels et personnels.
Transformation du travail : l’IA, menace ou alliée ?
L’arrivée de l’IA à grande échelle bouleverse d’ores et déjà le monde du travail. Jamais une technologie n’avait eu le potentiel d’automatiser autant de tâches intellectuelles de manière aussi fine. Ce constat suscite à la fois espoirs d’un gain de productivité inédit et craintes de destructions d’emplois massives. La réalité à court terme semble se situer entre ces deux extrêmes : l’IA agit surtout comme un accélérateur et un amplificateur du travail humain, même si certains métiers commencent à ressentir la pression de l’automatisation.

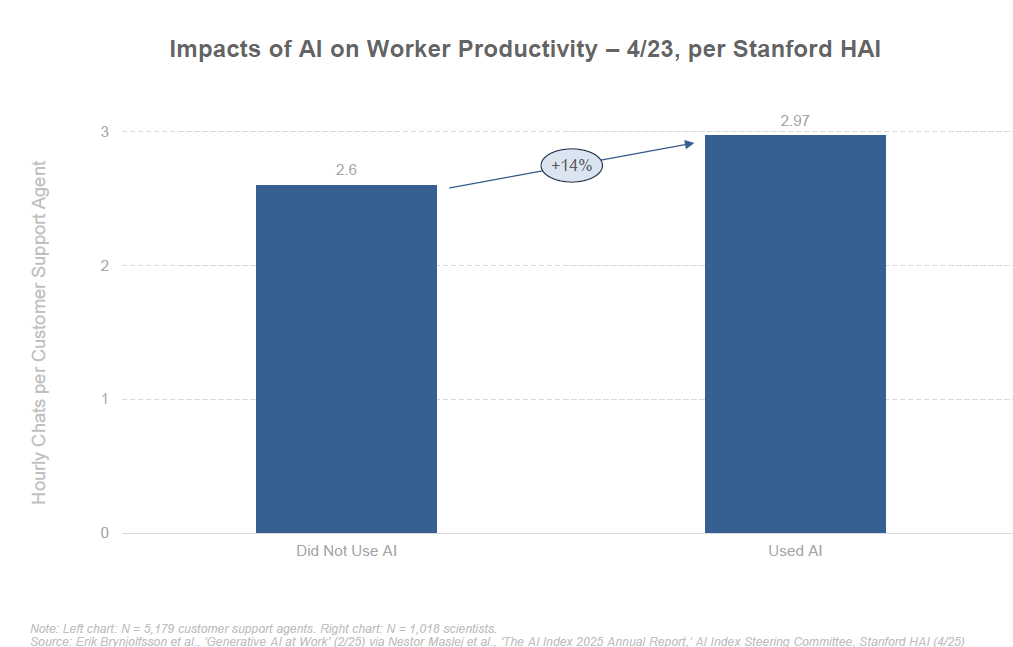
Côté optimiste, de nombreuses enquêtes montrent que l’IA augmente l’efficacité des travailleurs qui l’adoptent. Aux États-Unis, 72% des employés qui utilisent des chatbots d’IA au travail estiment que ces outils les aident à accomplir leurs tâches plus vite et mieux. L’IA sert souvent d’assistant intelligent, déchargeant les travailleurs des corvées répétitives : rédaction de brouillons d’emails, synthèse de documents volumineux, génération de code de base, réponse instantanée à des questions clients fréquentes, etc. Par exemple, des ingénieurs logiciels ont pu augmenter leur productivité de 20 à 50% en utilisant un assistant de codage type Copilot. Des rédacteurs marketing génèrent des ébauches de contenu que l’humain n’a plus qu’à affiner. Des équipes service-client utilisent des chatbots pour traiter instantanément les requêtes simples, réservant les cas complexes aux opérateurs humains.
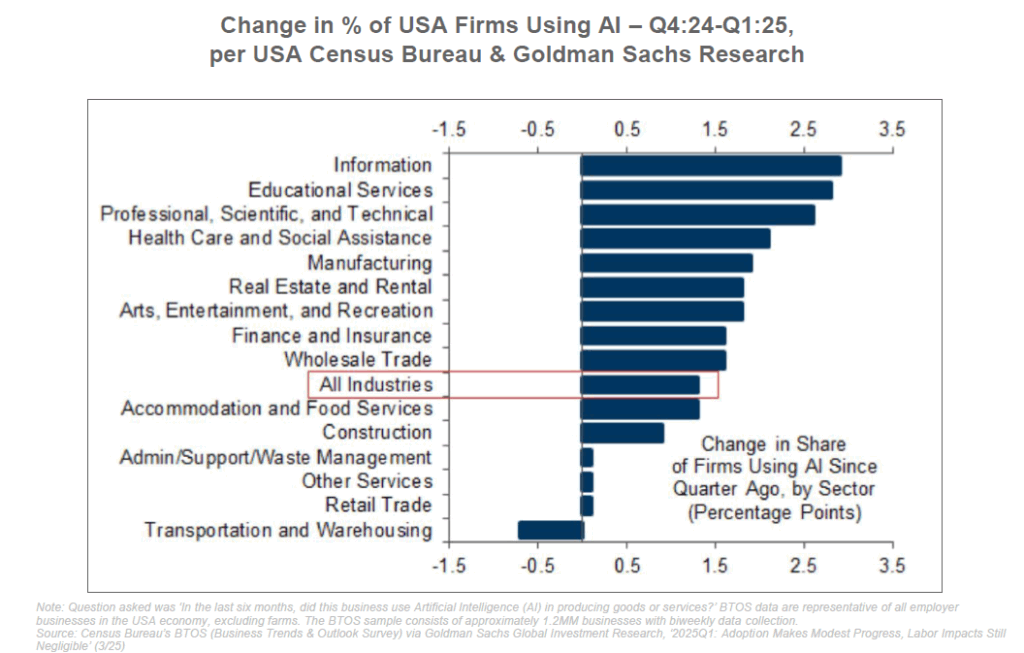
Les cadres dirigeants eux-mêmes s’emparent de ces outils : environ 75% des directeurs marketing (CMO) dans le monde testent ou utilisent déjà des solutions d’IA pour améliorer leurs campagnes, personnaliser le contenu et analyser les données plus efficacement. Les gains potentiels en productivité sont tels que Goldman Sachs estime que l’adoption généralisée de l’IA pourrait augmenter le PIB mondial de +7% sur une décennie – un boost économique majeur. On parle d’une nouvelle ère de “co-bots” (robots collaboratifs) intellectuels, où humains et IA travaillent main dans la main.
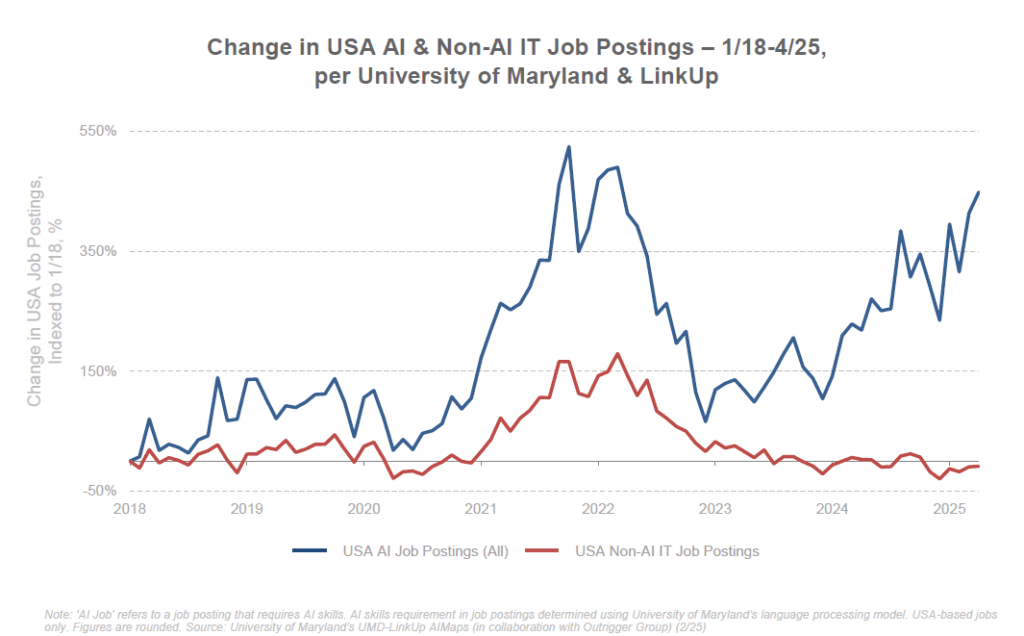
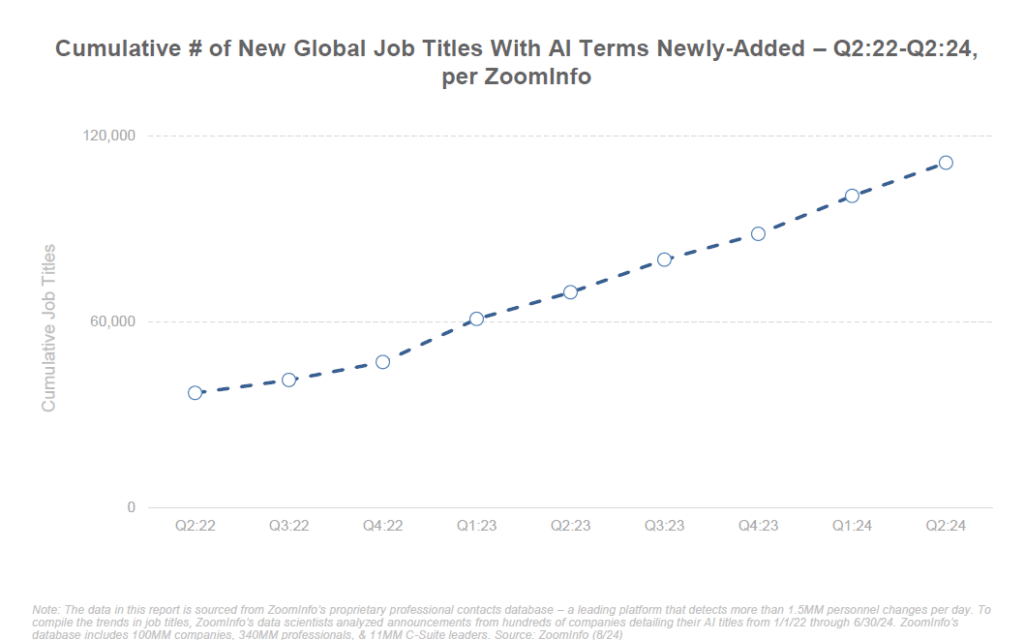
Des nouveaux métiers émergent d’ailleurs, reflet de cette complémentarité : prompt engineer (spécialiste de l’art de dialoguer avec les IA pour en tirer le meilleur), AI trainer (pour affiner les modèles avec du retour humain), spécialiste en éthique de l’IA, ou encore gestionnaire de projets d’automatisation. L’IA devient une compétence à part entière recherchée sur le CV. Les offres d’emploi liées à l’IA ont bondi de +448% en 7 ans selon une étude, témoignant de la création d’opportunités autour de cette technologie.
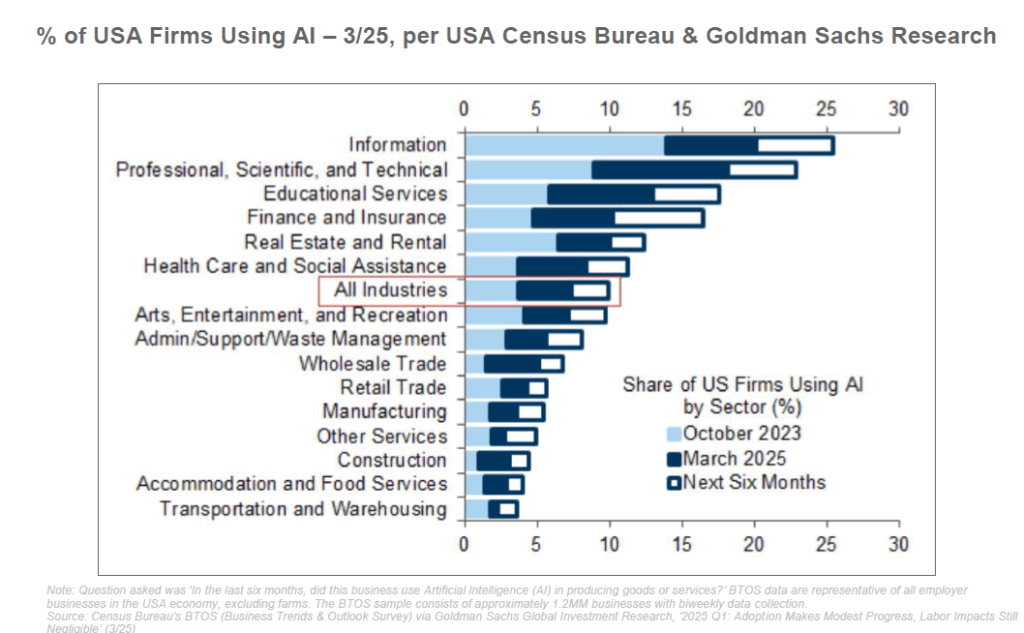
Cependant, l’autre versant de la médaille ne doit pas être ignoré. De nombreux emplois voient leur contenu transformé, voire menacé, par l’automatisation de certaines de leurs tâches. Un rapport de Goldman Sachs (2023) estimait que les outils d’IA générative pourraient exposer jusqu’à 300 millions d’emplois à travers le monde à une forme d’automatisation. Concrètement, la banque anticipait qu’environ un quart des tâches actuelles pourraient être effectuées par l’IA dans des économies avancées comme les USA ou l’Europe. Les secteurs administratifs, la comptabilité, le juridique, la traduction, ou certains métiers de bureau très routinier seraient les plus touchés (jusqu’à 40-50% des tâches automatisables). À l’inverse, des domaines manuels ou nécessitant une présence physique (maintenance, construction, petite enfance…) seraient relativement épargnés (moins de 5-10% des tâches automatisables).
Il est important de noter que “tâches automatisables” ne signifie pas disparition pure et simple de l’emploi correspondant. Historiquement, l’automatisation élimine certaines missions mais en créé de nouvelles, et beaucoup de métiers évoluent sans disparaître. Par exemple, un avocat disposant d’une IA pour rédiger des notes ou analyser des jurisprudences pourra traiter plus de dossiers, se concentrant sur le conseil stratégique et la plaidoirie – son rôle change, mais n’est pas obsolète pour autant. De même, un médecin verra son diagnostic assisté par IA, mais son empathie et son jugement clinique resteront clés. L’IA pourrait ainsi “augmenter” la plupart des professionnels plutôt que les remplacer entièrement dans un premier temps.
Néanmoins, certains emplois risquent d’être durement impactés si l’IA progresse encore : la création de contenu standardisé (rédaction web, rapports…), la modération en ligne, la saisie de données, ou le support client de niveau 1 pourraient se raréfier en tant qu’emplois humains. Les travailleurs de la connaissance sont contraints de monter en compétence pour se démarquer de ce que l’IA peut faire. La valeur se déplacera sans doute vers des tâches à plus haute valeur ajoutée : créativité véritable, expertise pointue, relation humaine personnalisée, ou supervision de l’IA elle-même.
Les entreprises, quant à elles, doivent gérer cette transition prudemment. Introduire l’IA en milieu de travail nécessite de former le personnel, de redéfinir des processus, et d’assurer une acceptation sociale. Beaucoup d’organisations choisissent pour l’instant l’approche “IA + humain” (les outils d’IA comme assistants) plutôt que de chercher à remplacer purement et simplement le personnel. Cela permet d’améliorer l’efficacité sans briser la confiance ni perdre le savoir-faire humain. Les syndicats et gouvernements commencent à se pencher sur la question afin d’anticiper les reconversions nécessaires dans les métiers menacés.
En France par exemple, des discussions ont lieu pour adapter les programmes de formation continue, encourager l’apprentissage des outils numériques et de l’IA à tous les niveaux, et éventuellement réduire le temps de travail sans perte de salaire si l’augmentation de productivité le permet (partage des gains de productivité). Certains plaident pour la création d’un “compagnon IA” pour chaque travailleur, c’est-à-dire garantir l’accès à des assistants intelligents comme un droit à l’outillage numérique, afin que personne ne soit laissé pour compte dans cette montée en productivité.
En définitive, l’IA transforme le travail, mais la manière dont cette transformation se traduira (utopie d’un travail affranchi des tâches ingrates, ou dystopie d’un chômage technologique de masse) dépendra largement des décisions politiques et sociétales. Les données actuelles suggèrent un potentiel de boom de productivité et de nouvelles richesses, à condition d’accompagner le changement : requalification des travailleurs, répartition équitable des bénéfices de l’automatisation, et éventuellement de nouveaux filets de sécurité (revenu universel d’activité financé par la productivité accrue, etc.) en cas de déséquilibre.
Défis pour l’éducation : entre opportunités pédagogiques et triche 2.0
Le système éducatif est un autre domaine bousculé par l’irruption de l’IA générative. En 2023, la disponibilité de ChatGPT au grand public a pris de court de nombreux enseignants : soudain, les élèves disposaient d’un outil capable de rédiger des dissertations, résoudre des problèmes de maths ou traduire un texte en quelques secondes, et ce gratuitement. On a vite parlé d’une “nouvelle calculatrice”, voire d’une menace pour l’évaluation traditionnelle. Plusieurs universités et lycées, d’abord méfiants, ont tenté de bannir l’utilisation de ChatGPT pour les devoirs par crainte de la triche et du plagiat. Des outils de détection de texte généré par IA ont été développés, sans réelle fiabilité hélas (les meilleurs détecteurs affichaient de nombreux faux positifs ou faux négatifs).
Face à cette réalité, le monde éducatif s’adapte progressivement. Un consensus émerge : au lieu d’interdire purement l’IA (ce qui est illusoire à long terme), il vaut mieux intégrer l’IA dans les pratiques pédagogiques et apprendre aux élèves à s’en servir à bon escient. Après tout, dans la vie professionnelle future, il est probable que les étudiants d’aujourd’hui utiliseront quotidiennement des assistants IA. Autant les former dès maintenant à “bien poser une question à l’IA”, à “vérifier et compléter une réponse IA”, etc. Par analogie, on n’interdit plus les calculatrices en cours de mathématiques, on apprend aux élèves à les utiliser intelligemment (tout en comprenant les concepts sous-jacents).
Plusieurs initiatives voient le jour : certains professeurs demandent aux élèves de co-créer avec l’IA (par exemple, générer un plan de dissertation avec ChatGPT puis le critiquer et l’améliorer manuellement, ou utiliser un outil d’IA pour obtenir des idées qu’il faudra ensuite organiser). L’IA peut aussi servir d’assistant d’apprentissage : on voit apparaître des tuteurs virtuels personnalisés qui répondent aux questions des élèves en s’adaptant à leur niveau, disponibles 24h/24. Khan Academy a par exemple intégré un agent nommé Khanmigo, basé sur GPT-4, qui dialogue avec l’élève pour l’aider à comprendre une notion sans donner la réponse directement – un peu comme un professeur particulier patient et toujours disponible.
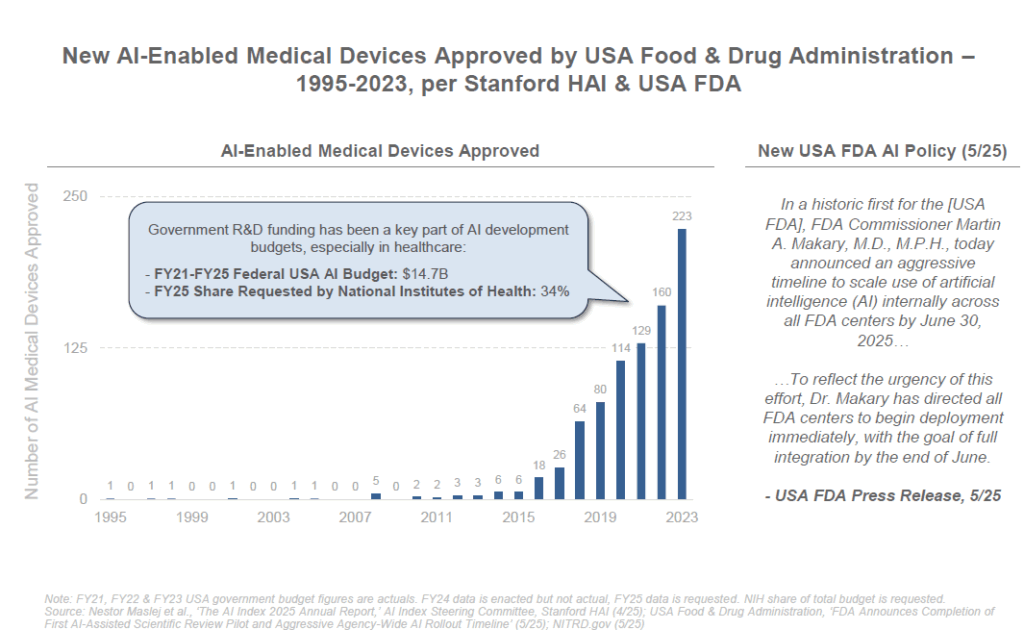
C’est une technologie qui va également servir dans le monde de la recherche avec des gains d’efficacité dans de très nombreuses disciplines.
De nombreux étudiants utilisent couramment des IA comme ChatGPT pour les recherches, l’aide aux devoirs ou la préparation d’examens. Plutôt que de nier cette réalité, les enseignants travaillent à redéfinir les méthodes d’évaluation pour valoriser les compétences non automatisables : oral, travaux de groupe en classe, analyse critique… Le défi est de maintenir l’intégrité académique (s’assurer qu’un élève a bien acquis des connaissances, et ne se repose pas aveuglément sur l’IA) tout en exploitant les formidables opportunités pédagogiques offertes par ces outils. J’ai constaté le même genre de choses en France dans mon enquête FNEGE.
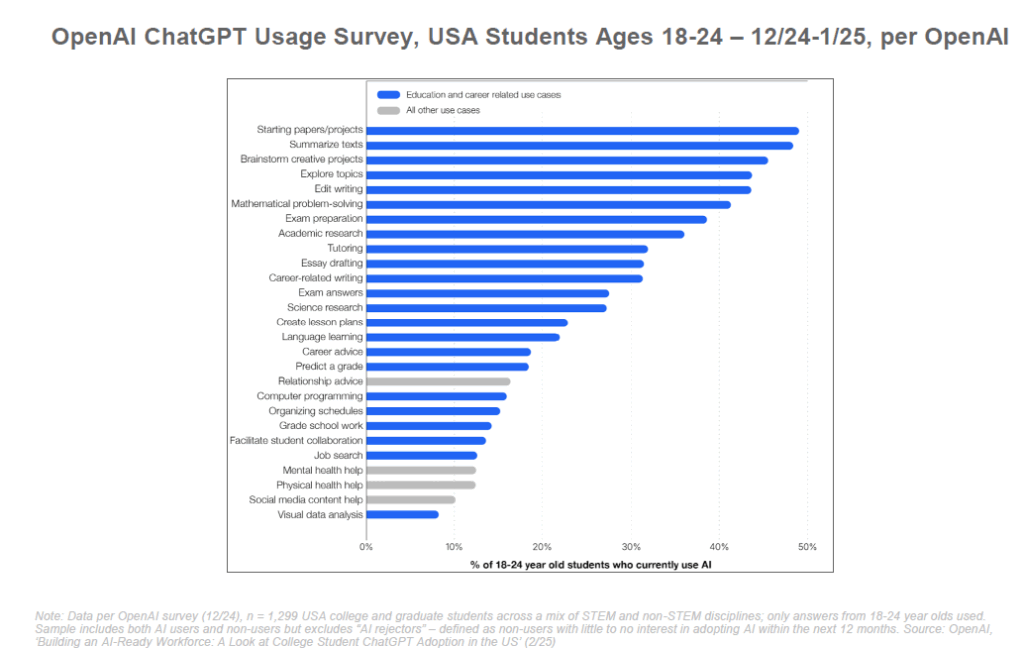
En effet, l’IA peut potentiellement personnaliser l’éducation à grande échelle. Chaque élève pourrait avoir un tuteur IA adapté à son rythme : accélérant pour les plus avancés, réexpliquant différemment pour ceux en difficulté, fournissant des exercices supplémentaires ciblés sur les lacunes de chacun. C’est la promesse d’une instruction différenciée enfin accessible, là où un enseignant humain pour 30 élèves ne peut individualiser entièrement son suivi. De plus, l’IA peut rendre l’apprentissage plus ludique et interactif (expliquer un concept sous forme de dialogue, créer des quiz instantanément, etc.).
Cependant, il faut rester vigilant sur plusieurs points. D’abord la qualité et fiabilité des réponses de l’IA : on l’a vu, ces modèles peuvent produire des erreurs factuelles convaincantes (hallucinations). Pas question donc de les laisser enseigner des contre-vérités – un encadrement par l’enseignant ou par des ressources vérifiées est nécessaire. Ensuite, il y a le risque d’une dépendance des élèves à l’outil : si on ne leur apprend pas d’abord les bases (par ex, savoir rédiger un essai sans IA, savoir faire un calcul mental), l’IA pourrait devenir un béquille qui affaiblit certaines compétences fondamentales. Il faudra trouver le bon équilibre, comme on l’a fait avec la calculatrice ou Wikipédia. Enfin, l’égalité des chances est un enjeu : veiller à ce que tous les élèves aient accès aux outils IA et sachent les utiliser, pour ne pas creuser davantage la fracture numérique.
De façon plus philosophique, l’IA invite aussi l’école à redéfinir ses objectifs. Si mémoriser des faits ou appliquer mécaniquement une méthode peut être fait par une machine, l’éducation devra mettre encore plus l’accent sur la compréhension, l’esprit critique, la créativité, la collaboration humaine – bref, tout ce qui fait la spécificité humaine par rapport aux intelligences artificielles. L’IA peut alors être vue non comme un ennemi, mais comme un catalyseur pour faire évoluer les pratiques pédagogiques vers plus de sens et d’efficacité. Nombre d’enseignants partagent ainsi l’avis qu’il faut “apprendre avec l’IA, non contre elle”. Les programmes scolaires commencent à inclure une sensibilisation à l’IA (comment elle fonctionne, ses biais, etc.), pour former des citoyens éclairés face à ces nouveaux outils.
C’est d’autant plus nécessaire qu’il est déjà possible de constater un fossé générationnel important que j’avais déjà souligné il y a plusieurs mois. Ainsi aux USA, 55% des 18-29 ans utilisent ChatGPT vs. 30% des 50-64 ans.
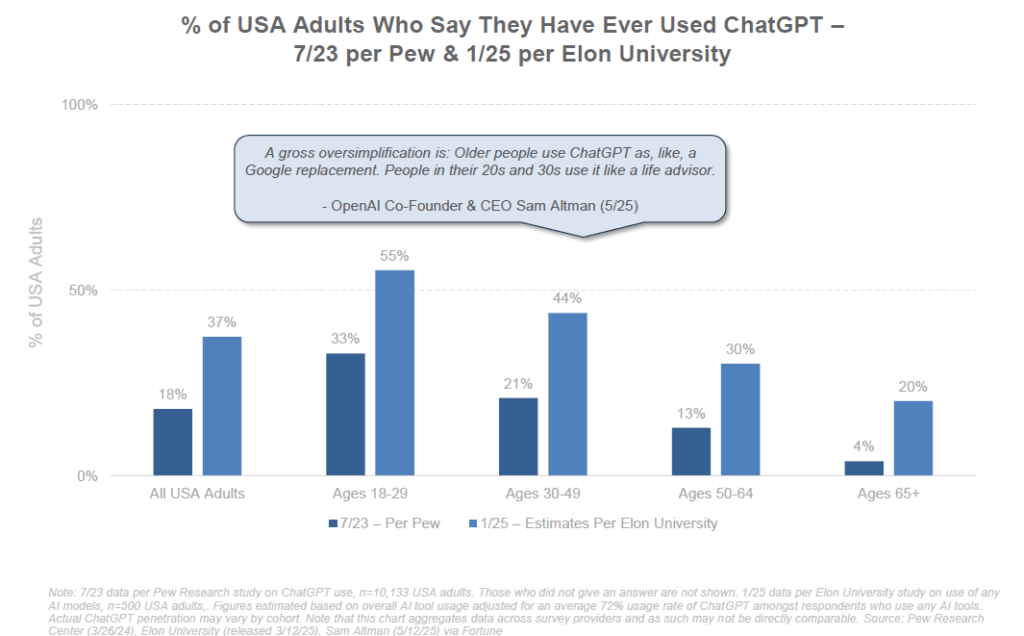
En conclusion, dans le domaine de l’éducation comme ailleurs, l’IA apporte son lot de perturbations, mais peut aussi devenir une alliée puissante pour relever le défi d’une instruction de qualité pour tous. Le chemin n’est pas encore tracé, et l’expérimentation en cours dans les classes du monde entier nous dira quelle est la meilleure manière d’intégrer cette révolution dans l’apprentissage des générations futures. C’est aussi pour cela que j’ai enclenché des actions de formation IA auprès des professeurs de classes préparatoires.
Nouvelles interfaces homme-machine : l’ère de l’assistant universel
L’intelligence artificielle de 2025 modifie profondément la façon dont nous interagissons avec les machines. Nous entrons dans l’ère des interfaces conversationnelles et multimodales, où la frontière entre l’outil et l’utilisateur s’estompe au profit d’un dialogue naturel. Plutôt que d’apprendre à parler le langage des logiciels (menus, formulaires, code), nous apprenons à parler avec l’IA… et l’IA apprend à nous comprendre en langage humain.
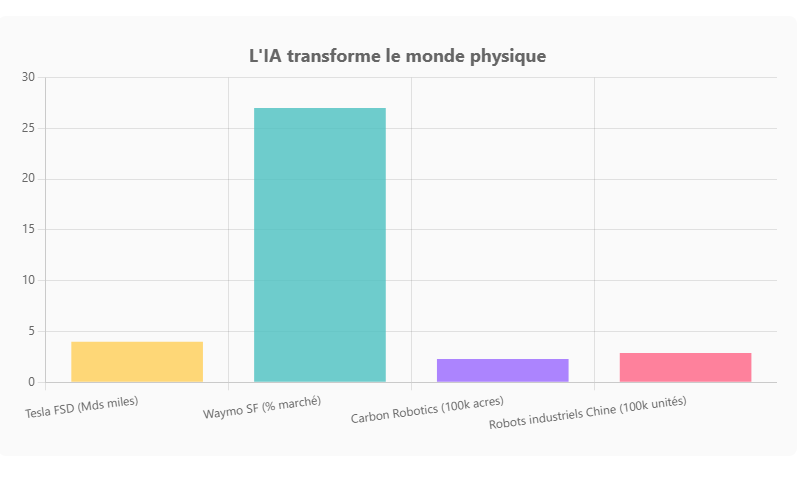
Un des développements marquants est l’arrivée d’assistants vocaux ultra-sophistiqués. OpenAI a, par exemple, doté ChatGPT de capacités de parole et de vision en 2023 : il est devenu possible de discuter à voix haute avec le chatbot et même de lui montrer des images sur mobile. Cela transforme le smartphone en un assistant virtuel bien plus intelligent que Siri ou Alexa ne l’avaient jamais été jusque-là. On peut parler à ChatGPT comme on le ferait avec une personne, lui demander de décrire ce qu’il voit sur une photo, ou de nous raconter une histoire du soir – et il répond avec une voix synthétique étonnamment naturelle. Cette évolution rend l’interface plus intuitive pour le grand public, y compris les enfants ou les personnes peu à l’aise avec l’écrit. « Ces nouvelles capacités voix et image offrent une interface plus intuitive, permettant d’avoir une conversation vocale ou de montrer ce dont on parle à l’IA », explique OpenAI. En clair, l’IA s’adapte à nos modes de communication (parole, vision), plutôt que l’inverse.
Dans la vie quotidienne, cela préfigure des appareils nettement plus “smart”. Les fabricants intègrent ces modèles conversationnels dans les objets du quotidien : assistants domestiques (enceintes connectées) capables de dialogues complexes, voitures dotées d’IA copilote vocale pour naviguer ou gérer les options, etc. Amazon a annoncé une refonte de son assistant Alexa en l’adossant à un LLM, pour le rendre plus conversationnel et contextuel dans la maison. De même, Meta a introduit des “IA personas” dans ses applications (WhatsApp, Instagram) qu’on peut interpeller en langage naturel pour diverses aides. Microsoft, avec Copilot, intègre un assistant IA directement au cœur de Windows 11 et de la suite Office : on peut demander à l’ordi “résume-moi ces 5 documents et fais une présentation PowerPoint des points clés”, et l’IA s’exécute en quelques instants. C’est un changement de paradigme : nos logiciels ne sont plus de simples outils passifs, ils deviennent des collaborateurs actifs, compréhensifs et capables d’initiative pour nous aider.

Les interfaces deviennent aussi multimodales : on peut fournir du texte, de la voix, des images, voire de la vidéo à l’IA, et recevoir en retour une réponse adaptée. Prenons un exemple concret : vous pouvez prendre en photo le contenu de votre réfrigérateur et demander à l’IA “Qu’est-ce que je peux cuisiner avec ça ?” – elle analysera l’image, identifiera les ingrédients et proposera une recette, éventuellement en vous guidant pas à pas. Ce type d’interaction, très naturelle, aurait semblé de la science-fiction il y a peu. Désormais, c’est à portée de main grâce aux modèles multimodaux (comme GPT-4 vision). De même, en voyage, pointer l’appareil photo de son téléphone vers un monument et demander “Quelle est l’histoire de ce bâtiment ?” pourra offrir une mini-visite guidée instantanée.
Les réalités virtuelle et augmentée profiteront sans doute aussi de ces avancées. Imaginez un assistant AR (lunettes à réalité augmentée + IA) qui vous souffle dans l’oreille des informations contextuelles sur ce que vous regardez, ou vous aide à réaliser une tâche manuelle en affichant des annotations en temps réel dans votre champ de vision. Si vous bricolez quelque chose, l’IA pourrait reconnaître l’étape et vous guider (“tourne ce boulon d’un quart de tour à gauche”, etc.). Des compagnies comme Apple planchent sur l’intégration d’IA dans leurs dispositifs (même si, au lancement du Vision Pro en 2024, l’accent n’était pas encore mis explicitement sur l’IA générative, on peut s’attendre à ce que cela vienne). L’IA permettra en tout cas de rendre les interfaces homme-machine plus naturelles, contextualisées et proactives.
Par ailleurs, l’IA générative permet de créer des contenus sur mesure via de simples instructions, ce qui abaisse énormément la barrière de la création. Cela vaut pour le texte, mais aussi pour l’image (outils comme DALL-E, Midjourney génèrent des illustrations à la demande), le son (il existe des IA qui synthétisent de la musique ou imitent une voix à partir de quelques samples), et même la vidéo (les premiers générateurs vidéo IA commencent à apparaître). On se dirige vers des interfaces où l’utilisateur décrit ce qu’il veut et la machine le réalise. Par exemple, au lieu de chercher manuellement dans un éditeur d’image, on pourra dire “fais-moi un logo montrant un chat bleu souriant avec un chapeau” – et l’IA graphique le produira en quelques secondes. De tels outils existent déjà, même s’ils ne remplacent pas encore des graphistes experts, ils dépannent pour de la maquette rapide ou des besoins simples. De même en programmation : le développeur peut décrire en langage courant la fonction qu’il veut coder, et l’assistant codeur génère l’ébauche de code correspondante.
Ces interfaces dites “de haut niveau” libèrent la créativité et l’accessibilité. Des personnes sans formation peuvent réaliser des choses autrefois réservées aux experts (dessiner, composer, monter une vidéo, programmer basiquement…). On parle de “baisse du seuil” de création : moins de compétences techniques requises pour concrétiser une idée. En corollaire, le “plafond” (qualité maximale atteignable) s’élève aussi avec l’IA comme aide pour les professionnels.
Bien sûr, cette nouvelle donne pose aussi des questions : comment préserver le contrôle humain et éviter que l’IA n’impose ses propres choix d’interface ? Les premiers retours utilisateurs notent que discuter avec une IA très avancée peut donner l’illusion d’une relation quasi-humaine (avec le risque d’anthropomorphisme excessif, ou de dépendance émotionnelle pour des personnes vulnérables). Il faut concevoir ces systèmes de façon transparente (l’utilisateur doit toujours savoir qu’il parle à une machine) et respectueuse (protéger la vie privée, ne pas manipuler l’utilisateur). De même, une interface en langage naturel est puissante mais ambiguë : la machine peut mal interpréter une demande floue. Un défi est donc de créer des IA capables de demander des précisions intelligemment si l’ordre n’est pas clair, à l’image d’un assistant humain consciencieux.
Malgré ces précautions, l’avènement de l’IA comme nouvelle couche d’interaction universelle semble inévitable. Chaque grande transition informatique (clavier-souris, écrans tactiles, commande vocale) a rapproché l’outil de nos modes de communication naturels. L’IA conversationnelle accomplit cette vision de l’ordinateur-compagnon, toujours disponible pour nous aider de manière relativement fluide. En 2030, il est plausible que nous parlions couramment à nos appareils (smartphones, lunettes, voitures, électroménager) et qu’ils nous répondent de façon pertinente, le tout orchestré par des IA intégrées et interconnectées. L’interface disparaîtra presque, au profit de l’intention : on exprime ce qu’on veut, et la machine s’occupe du reste. C’est à la fois grisant en termes de possibilités, et responsabilisant quant à l’usage qu’on en fera.
La course géopolitique de l’IA : une nouvelle guerre froide technologique
L’intelligence artificielle est désormais au cœur d’une compétition géopolitique intense, souvent décrite comme la « course à l’IA ». Deux superpuissances dominent cette course : les États-Unis et la Chine. Derrière, l’Europe cherche sa voie, oscillant entre rattrapage technologique et régulation préventive, tandis que d’autres pays tentent de se positionner sur des niches ou par des alliances.
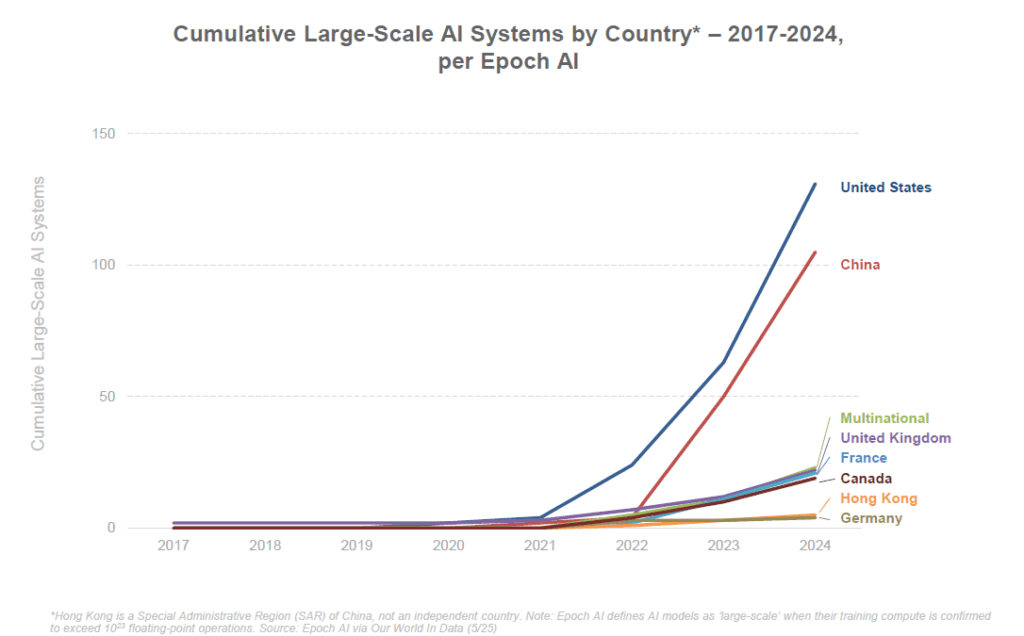
États-Unis : leadership de l’innovation, emprise des Big Tech
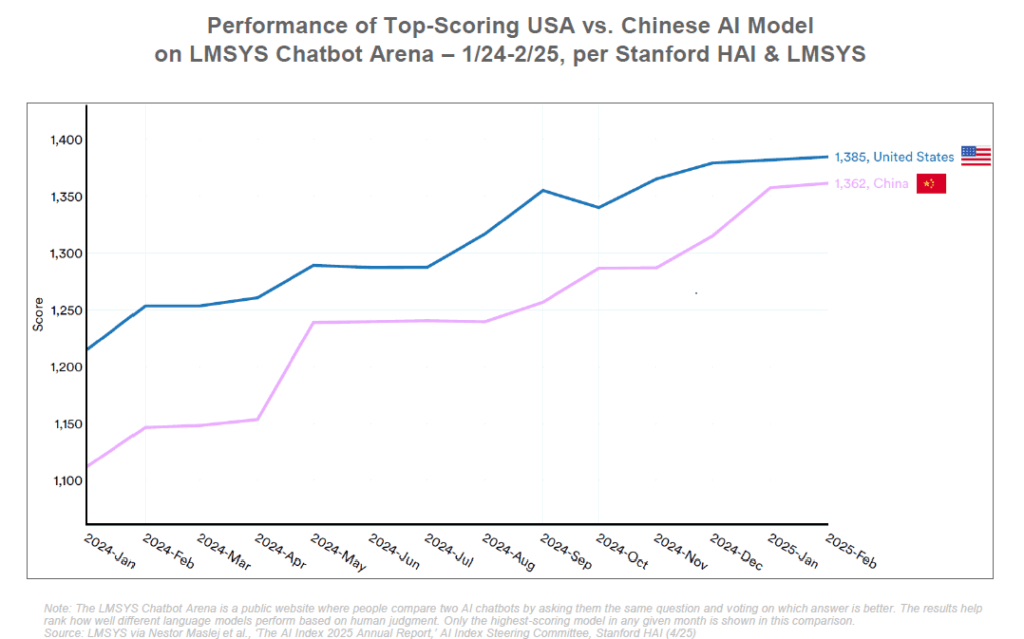
Les États-Unis conservent pour l’instant une avance significative dans plusieurs dimensions de l’IA. Selon le rapport BOND, les entreprises et laboratoires américains ont produit environ 40 des modèles d’IA marquants en 2024, plus que tout autre pays. Des firmes comme OpenAI, Google, Meta, Microsoft, IBM, Anthropic… constituent un écosystème d’innovation sans équivalent. OpenAI a été l’organisation la plus prolifique, avec 7 modèles majeurs publiés en 2024, consolidant son statut de leader dans les systèmes d’IA généralistes.
Ce dynamisme s’appuie sur des investissements colossaux (cf. explosion du CapEx évoquée plus haut) et un terreau de talents attirés du monde entier. Les États-Unis possèdent nombre des meilleures universités et centres de recherche en IA, et attirent les chercheurs via des opportunités en startups ou grands groupes. D’après Jensen Huang (CEO de NVIDIA), environ 50% des chercheurs mondiaux en IA travaillent en Chine et une bonne partie du reste aux États-Unis. La compétition pour les talents est donc principalement entre ces deux pays, avec l’Inde, l’Europe, le Canada comme autres pôles d’importance moindre.
L’administration américaine voit dans l’IA un enjeu stratégique, à la fois économique et militaire. Depuis 2019, les États-Unis affirment vouloir “garder la suprématie de l’IA”. Sous l’ère Trump, un premier plan national pour l’IA a été lancé, et sous Biden cela s’est accéléré : investissements fédéraux en R&D, partenariats public-privé, mise en réseau des supercalculateurs nationaux, etc. En 2022, un “AI Bill of Rights” (non contraignant) a été proposé pour encadrer les usages publics de l’IA et protéger les citoyens, mais la législation en est encore à ses débuts. Fin 2023, la Maison Blanche a obtenu de plusieurs grandes entreprises d’IA un engagement volontaire à soumettre leurs modèles à des évaluations de sécurité, à partager des informations sur les risques, et à intégrer des outils de watermarking pour signaler les contenus générés.
Sur le plan militaire, le Pentagone investit dans l’IA pour conserver son avantage : drones autonomes, analyse automatique des renseignements, cyberdéfense pilotée par IA… La DARPA (agence de recherche de défense) finance de nombreux projets liant IA et robotique. L’IA est perçue comme la clé des “armes du futur”, aux côtés de la quantique et de la biotechnologie. En 2020, le Pentagone a créé le Joint AI Center (JAIC) pour coordonner l’adoption de l’IA dans l’armée.
Conscient que l’IA dépend aussi de l’infrastructure matérielle, les États-Unis ont pris des mesures pour préserver leur avance en semi-conducteurs. Une date clé : octobre 2022, où Washington a décrété de strictes restrictions d’exportation des puces IA vers la Chine. Les fameux GPU A100 et H100 de NVIDIA, indispensables pour entraîner des modèles géants, ne peuvent plus être librement vendus à la Chine. L’objectif affiché est de freiner les progrès militaires chinois en privant le pays des composants les plus avancés, et de conserver la domination américaine sur l’infrastructure de l’IA. Ces sanctions ont un coût (NVIDIA a perdu une part énorme de son marché chinois et a dû concevoir des versions bridées de ses puces pour contourner partiellement l’interdit), mais elles illustrent bien l’enjeu : la maîtrise de l’IA passe par la maîtrise des chips et des data centers. C’est un levier géopolitique majeur.
Chine : l’offensive tous azimuts, du quantitatif à l’open source
La Chine, de son côté, a fait de l’IA une priorité nationale. Dès 2017, le gouvernement chinois a publié un plan ambitieux visant à faire de la Chine le leader mondial de l’IA d’ici 2030. Les investissements publics et privés chinois en IA se comptent en dizaines de milliards de dollars. Un écosystème florissant d’entreprises d’IA est né, avec des géants comme Baidu, Alibaba, Tencent, Huawei et une myriade de startups innovantes (SenseTime, Megvii, iFlyTek, etc.). La Chine excelle notamment en vision par ordinateur (reconnaissance faciale déployée massivement), en big data (soutenu par sa base d’utilisateurs immense) et désormais en LLM open source comme on l’a vu.
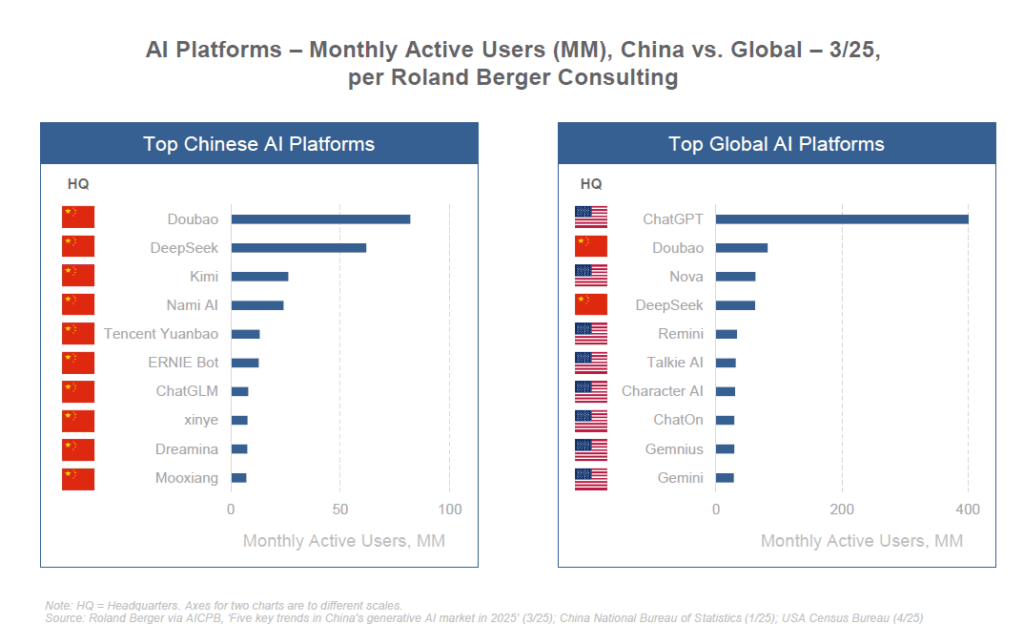
Les restrictions américaines sur les puces ont paradoxalement stimulé la Chine à accélérer son autonomie. Comme le dit Jensen Huang, “les ingénieurs locaux sont très talentueux et déterminés, et le contrôle à l’export a redoublé leur énergie avec le soutien du gouvernement”. Privée des meilleurs GPU américains, la Chine investit dans ses propres filières de composants (entreprises comme Biren, Huawei avec son Ascend, Alibaba avec son Hanguang) et optimise les modèles pour faire plus avec moins (cf. DeepSeek qui prétend avoir entraîné un modèle rival de GPT-4 avec seulement 2000 GPU et 3 M$). D’ailleurs, une entreprise chinoise, DeepSeek, a fait parler d’elle début 2025 en annonçant avoir drastiquement réduit les coûts d’entraînement (×18 plus efficient que GPT-4o d’OpenAI) et d’inférence (×36 plus efficient) grâce à des innovations algorithmiques. Même si ces chiffres sont à prendre avec prudence, ils montrent que la Chine cherche des voies alternatives et plus efficientes pour atteindre le sommet de l’IA.
Le gouvernement chinois orchestre une stratégie holistique : d’un côté, un soutien massif aux infrastructures (construction accélérée de centres de données, subventions pour l’achat de GPU, création de parcs technologiques dédiés). Un rapport récent du Special Competitive Studies Project souligne un “boom des infrastructures IA en Chine” piloté par l’État, avec la construction de data centers géants et même des plans qui s’étendent “au-delà de l’atmosphère terrestre” pour installer des serveurs en orbite – perspective futuriste qui montre l’échelle à laquelle pense la Chine. De l’autre côté, la régulation chinoise impose un cadre idéologique : depuis 2023, des règles sur les IA génératives exigent que les modèles respectent les valeurs socialistes et ne produisent pas de contenu politiquement sensible ou subversif. Chaque modèle d’IA grand public doit être licencié par l’État, et les plateformes doivent vérifier l’identité des utilisateurs. Cela pourrait freiner la créativité, mais assure au Parti communiste un contrôle sur cette technologie stratégique et sur l’information qu’elle diffuse.
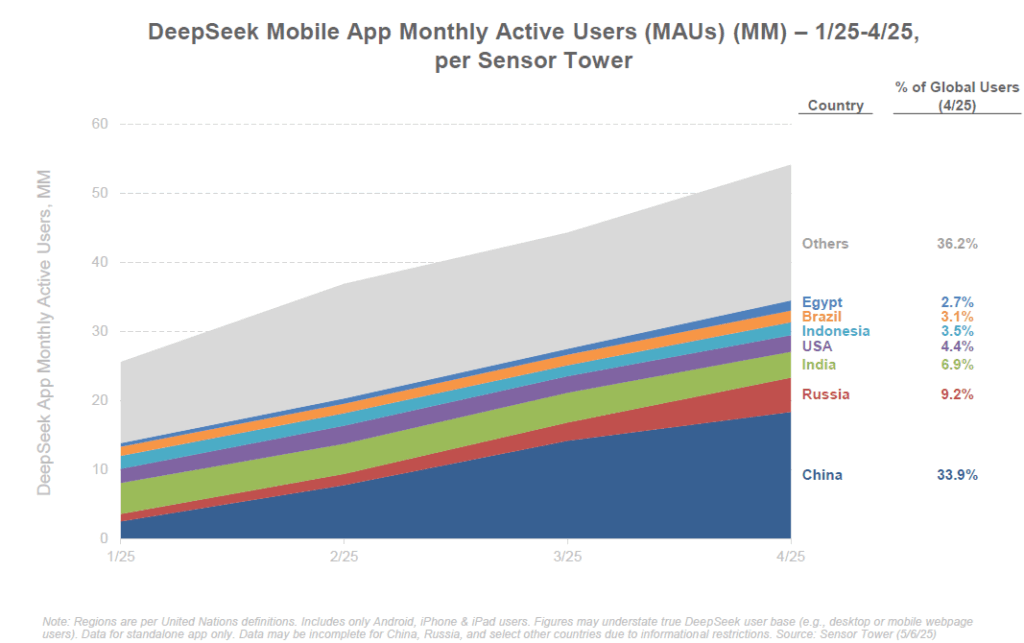
La Chine mise aussi fortement sur la communauté open source locale. Comme mentionné, elle est en tête sur la publication de grands modèles open source en 2025. Le gouvernement encourage les entreprises à open-sourcer certaines de leurs avancées non sensibles pour bâtir un écosystème local robuste, tout en réduisant la dépendance aux outils occidentaux. Par exemple, Baidu a rendu open source certaines versions d’ERNIE, son modèle de langage. Des modèles comme MOSS (équivalent de ChatGPT développé par l’université Fudan) ou Ziya (Tsinghua) témoignent de la vitalité académique.
Sur le plan militaire et sécurité, la Chine intègre l’IA à sa doctrine de guerre informatisée : systèmes de surveillance de masse boostés à l’IA, drones autonomes, guerre cognitive (deepfakes, désinformation algorithmiquement pilotée). Cela alarme Washington, qui craint une bascule du rapport de force si la Chine prenait l’avantage en IA militaire. D’où une réthorique américaine comparant la course à l’IA à la course à l’armement nucléaire de la Guerre froide, où “gagner la course à l’IA” est perçu comme vital pour la sécurité nationale.
Europe et reste du monde : l’option régulation et collaborations
Face à ces deux géants, l’Europe cherche à exister sur la scène de l’IA, mais accuse un certain retard en termes d’acteurs majeurs. Aucune entreprise européenne n’a encore produit de modèle de langage du calibre de GPT-4 ou d’équivalent en vision. Néanmoins, l’Europe a un atout différenciant : son pouvoir normatif et sa volonté d’encadrer la technologie. L’Union Européenne a ainsi négocié le tout premier cadre juridique global sur l’IA, appelé AI Act, adopté en 2024. Cette loi impose une classification des systèmes d’IA par niveau de risque, interdit certains usages jugés inacceptables (par ex, notation sociale étatique, surveillance biométrique de masse hors contexte sécurité, manipulation cognitive des enfants…) et exigera des obligations de transparence et d’évaluation pour les systèmes à risque élevé. Les premières dispositions (interdiction de quelques pratiques) entrent en vigueur début 2025, et le gros des obligations s’appliquera d’ici 2026-2027. L’UE espère ainsi “humaniser l’IA” et créer une confiance chez les citoyens, tout en évitant une situation de far-west technologique.
Cela étant, l’Europe sait qu’elle doit aussi investir : des programmes comme Horizon Europe allouent des fonds à la recherche en IA, et des pays comme la France ou l’Allemagne tentent de soutenir des alternatives locales (par ex, l’initiative franco-allemande pour des “générateurs de texte multilingues” open source). La France a quelques startups prometteuses (Mistral AI qui a sorti un modèle open source en 2023, Aleph Alpha en Allemagne, etc.). Le défi reste l’accès aux ressources de calcul et aux données, largement dominées par les GAFAM et BATX. D’où des discussions sur une possible souveraineté numérique : construire des clouds européens, encourager l’open data, etc.
Ailleurs dans le monde, d’autres acteurs entrent en jeu : le Japon investit beaucoup en IA, notamment via des collaborations public-privé (Fujitsu, Sony, et l’organisme Riken ont entraîné un grand modèle japonais Oogai). L’Inde, riche de talents en informatique, se positionne de plus en plus (beaucoup de développeurs indiens participent aux projets open source, et le gouvernement Modi pousse pour une stratégie IA “for All”). Des pays comme les Émirats arabes unis financent également des projets d’IA (les Émirats ont ainsi développé Falcon, un LLM open source compétitif, via l’institut TII d’Abu Dhabi). Il y a donc une multipolarité naissante sur certains aspects, même si globalement le duo USA-Chine domine en moyens et en avancées.
La compétition IA s’apparente ainsi à une course technologique globale, où chaque région tente de jouer ses cartes : innovation agile et capital-risque pour les États-Unis, planification étatique et volume de données pour la Chine, régulation et coopération internationale pour l’Europe, spécialisation et talents pour d’autres. Cette course n’est pas forcément à somme nulle : il y a des terrains de collaboration. Par exemple, plus de 40 pays (dont USA et Chine) ont signé en 2020 les principes de l’OCDE sur l’IA responsable. Un Partenariat mondial sur l’IA (GPAI) incluant l’Europe, l’Inde, etc., travaille sur des recommandations éthiques. En 2023, les Nations Unies ont commencé à évoquer la nécessité d’un cadre international, et le G7 a lancé le “Hiroshima AI Process” pour un dialogue sur la gouvernance de l’IA. Le Royaume-Uni a accueilli en novembre 2023 un sommet mondial sur la sécurité de l’IA à Bletchley Park, rassemblant experts et officiels pour discuter des risques à court terme (deepfakes, cyberattaques) mais aussi long terme (scénarios d’IA hors de contrôle). Ces efforts montrent une prise de conscience générale : l’IA, comme le climat, est un enjeu planétaire qui nécessite a minima une coordination, pour éviter les dérives catastrophiques tout en partageant ses bénéfices.
Néanmoins, les divergences persistent : entre une approche plutôt libérale/pro-innovation aux États-Unis, autoritaire en Chine, et precautionniste en Europe, trouver un terrain d’entente n’est pas simple. La concentration du pouvoir technologique entre quelques mains (principalement des multinationales américaines et chinoises) pose aussi un problème d’équité globale. Des voix appellent à “démocratiser” l’IA, via l’open source, le transfert de technologie vers les pays en développement, ou des mécanismes de licence obligatoires pour éviter un monopole de fait de quelques acteurs privés sur ce que certains considèrent désormais comme un bien commun (les modèles d’IA étant entraînés sur les données du public, après tout). Ce débat entre ouverture et contrôle national/international ne fait que commencer.
Risques et défis : biais, éthique, concentration… quelles limites pour l’IA ?
Malgré son potentiel extraordinaire, l’essor de l’IA s’accompagne d’un cortège de risques et de défis qu’il serait imprudent d’ignorer. Le rapport BOND, tout enthousiaste qu’il soit sur les tendances, consacre d’ailleurs une partie à ces écueils bien connus : hallucinations, biais, mésinformation, retard de la régulation…. Passons en revue les principaux enjeux négatifs associés à l’IA et les garde-fous envisagés.
- Biais et discrimination : Les modèles d’IA apprennent à partir de données existantes, qui peuvent contenir les biais de la société (stéréotypes sexistes, racistes, etc.). Sans correction, l’IA risque de reproduire voire amplifier ces biais dans ses décisions ou recommandations. On l’a vu avec des systèmes de recrutement favorisant les hommes parce que formés sur l’historique d’embauche interne (majoritairement masculin), ou des IA de reconnaissance faciale moins précises sur les visages de personnes noires (faute d’assez d’exemples dans les données d’entraînement). Les LLM comme ChatGPT peuvent, si on les y pousse, sortir des propos discriminatoires ou offensants parce que ces idées existent en masse sur Internet. Ce problème de biais algorithmique est crucial car l’IA est appelée à prendre part à des décisions sensibles (embauche, crédit bancaire, diagnostic médical…). Des efforts importants sont menés pour auditer les modèles, filtrer les données sensibles, et imposer des règles éthiques dans la génération (via le “alignement” des modèles avec des valeurs humaines). Néanmoins, éliminer complètement les biais est un défi technique et philosophique (quel “biais” est inacceptable et lequel reflète une réalité statistique qu’il faut garder ?). Il faudra une vigilance constante et probablement une régulation pour s’assurer que l’IA n’entérine pas des discriminations systémiques.
- Hallucinations et fiabilité : Les modèles génératifs ont une fâcheuse tendance à produire des affirmations factuellement fausses mais dites avec aplomb, qu’on appelle hallucinations. Par exemple, ChatGPT peut inventer une référence bibliographique de toutes pièces ou confondre deux événements historiques. Ces erreurs, dues à la manière dont le modèle devine la suite la plus probable sans “savoir” au sens humain, posent un souci de confiance. Dans des usages critiques (droit, médecine, information), s’appuyer sur une IA peut mener à des erreurs graves si on ne vérifie pas derrière. Réduire les hallucinations est un sujet de recherche actif : on augmente la qualité et fraîcheur des données, on connecte l’IA à des bases de connaissances fiables, on la pousse à formuler des incertitudes quand elle n’est pas sûre. Certains progrès ont lieu (GPT-4 hallucine moins que GPT-3), mais le risque zéro n’existe pas encore. Il faudra garder l’humain dans la boucle pour valider les outputs de l’IA, du moins tant qu’elle n’atteint pas un niveau de fiabilité éprouvé.
- Mésinformation et usages malveillants : Une IA qui peut générer du texte, de la vidéo, du son réalistes ouvre la porte à des deepfakes et des campagnes de désinformation à grande échelle. On a vu des cas d’arnaques téléphoniques où la voix d’un proche était imitée pour soutirer de l’argent. Sur les réseaux, on craint des flots de contenus fictifs créés par IA pour influencer l’opinion (élections, conflits…). Des images deepfake d’hommes politiques ou de fausses actualités générées pourraient saturer l’espace médiatique. La démocratie et la cohésion sociale peuvent en souffrir si la confiance dans l’information s’érode complètement. Là encore, il faudra des parades : authentification des sources, éducation des citoyens aux médias, watermarking (tatouage numérique) des contenus générés pour pouvoir remonter à la source IA. Les grandes entreprises d’IA ont promis de travailler sur ces marqueurs d’authenticité, mais techniquement ce n’est pas simple (un filigrane peut être contourné ou perdu lors d’une modification). L’arsenal législatif va aussi se muscler : imposer la mention obligatoire “image générée” etc., et punir sévèrement l’usage de deepfake malveillant (certains pays l’ont déjà fait pour la pornographie non-consentie deepfake).
- Concentration du pouvoir et dépendance : Comme évoqué, l’IA actuelle est dominée par quelques acteurs disposant des ressources massives requises (données, calculateurs, cerveaux). Cette concentration pose problème : une poignée de grandes entreprises (aux USA principalement) pourraient contrôler les systèmes d’IA utilisés par des milliards d’individus. Cela confère un pouvoir immense – potentiellement d’influence (si demain la moitié de l’humanité utilise un assistant d’une même compagnie, quel biais cette compagnie peut introduire ?), et financier (position ultra-dominante du marché). Déjà, OpenAI/Microsoft, Google, Meta, Amazon et quelques autres se partagent l’infrastructure mondiale de l’IA. On note aussi de plus en plus de collaborations oligopolistiques : par ex, Microsoft a investi 10 Mds$ dans OpenAI et intègre partout ses modèles, tandis que Amazon a un partenariat avec Anthropic, etc. Cette situation rappelle le début d’Internet dominé par quelques plateformes, mais avec un impact potentiellement encore plus profond sur toutes les industries. Les gouvernements, notamment en Europe, commencent à s’en inquiéter : risque de dépendance stratégique (l’UE dépendra-t-elle d’OpenAI/Microsoft pour son administration, sa défense ? Pas acceptable). D’où la volonté de souveraineté évoquée précédemment. Le concept de “bien commun” pour certains modèles d’IA est aussi débattu : par exemple, pourquoi ne pas considérer les LLM de base comme des infrastructures critiques à gouvernance partagée, un peu comme l’est Internet ? Des initiatives open source militent pour que l’IA ne soit pas l’apanage de quelques géants. En parallèle, des réflexions sur des anti-monopoles de l’IA pourraient émerger si un acteur devenait trop incontournable. L’Histoire a montré qu’une concentration extrême de la puissance techno-économique est néfaste pour l’innovation et la liberté : l’IA n’échappe pas à cette règle. Il faudra donc veiller à un équilibre entre innovation rapide (souvent portée par les grands acteurs) et distribution équitable des bénéfices et du contrôle.
- Sécurité et contrôle : À mesure que l’IA gagne en autonomie (voir section agents) et en ubiquité, la question se pose : comment garder le contrôle ? On veut éviter le fantasme de l’IA qui nous échapperait et causerait des dommages involontaires ou intentionnels (rogue AI). Sans aller jusqu’aux scénarios de science-fiction apocalyptiques, des risques concrets existent : une IA mal entraînée pilotant un véhicule autonome pourrait provoquer des accidents, un agent conversationnel connecté à internet pourrait s’emballer et lancer des attaques (il y a eu des cas d’autoGPT qui tentaient de faire des choses étranges avant qu’on les arrête). La notion d’alignement de l’IA avec les objectifs humains est centrale : on développe des méthodes pour “contenir” les IA (par exemple des gouverneurs qui surveillent et corrigent les actions d’un agent si elles sortent d’un périmètre autorisé). La recherche en IA Safety vise aussi à anticiper les problèmes avant qu’ils ne surviennent. OpenAI, DeepMind et autres ont des équipes dédiées à tester leurs modèles (détection de comportements indésirables, évaluation des réponses toxiques, etc.). Mais plus l’IA sera puissante, plus il faudra redoubler d’ingéniosité pour garantir qu’elle reste sous contrôle. Certains experts appellent à un moratoire sur les IA trop avancées tant qu’on n’est pas sûrs de maîtriser leur alignement (lettre ouverte d’ELON Musk et d’autres en 2023 appelant à une pause sur les modèles plus puissants que GPT-4, par exemple). D’autres estiment qu’on peut continuer prudemment tout en renforçant la coopération internationale sur la sécurité (d’où le sommet de Bletchley Park et les tentatives de cadres globaux).
- Impact environnemental : Un point souvent oublié est l’empreinte écologique de l’IA. Entraîner un modèle comme GPT-4 aurait émis autant de CO2 que plusieurs centaines de vols long-courriers. Et l’inférence (utilisation au quotidien) consomme beaucoup d’énergie dans les data centers. Déjà, les centres de données consomment environ 1,5% de l’électricité mondiale, et ce chiffre monte avec l’IA. Aux États-Unis, les data centers liés à l’IA ont représenté 45% de la conso électrique mondiale des data centers. Si on ne fait rien, le risque est que l’IA devienne un gouffre énergétique, contraire aux objectifs climatiques. Heureusement, les gains d’efficacité (puces plus sobres, algos optimisés) contrebalancent en partie l’augmentation de la charge – mais pas entièrement (effet rebond type paradoxe de Jevons : plus c’est efficace, plus on en fait, donc la consommation totale peut grimper quand même). Il faudra donc penser IA durable : alimenter les data centers en énergies renouvelables, recycler la chaleur, et chercher des algorithmes green AI moins gourmands. Quelques entreprises se distinguent en calcul bas carbone, ce qui pourrait devenir un avantage compétitif si les préoccupations écologiques grandissent.
En synthèse, les risques de l’IA sont réels et multiples, mais loin d’être insurmontables. Ils appellent à la fois des solutions techniques (améliorer les modèles, les encadrer, les auditer) et politiques (lois, normes, coopérations internationales). Comme toute technologie puissante, l’IA est un couteau à double tranchant : elle peut amplifier le meilleur comme le pire de l’humanité. À nous de mettre en place les garde-fous pour minimiser le pire (injustices, désinformation, pertes de contrôle) et maximiser le meilleur (progrès, prospérité partagée, libération de tâches pénibles). Le plus grand risque serait peut-être de négliger ces enjeux et de laisser l’IA évoluer plus vite que notre capacité à l’appréhender collectivement.
Conclusion : l’IA en 2030, promesses et inconnues
En l’espace de quelques années, l’intelligence artificielle est passée du statut de technologie de niche à celui de force transformatrice mondiale. Le rapport de Mary Meeker brosse un tableau sans équivoque : l’IA connaît une croissance exponentielle, qu’il s’agisse de son adoption par les utilisateurs, de ses capacités techniques ou des investissements qui la soutiennent. Cette dynamique s’accompagne d’une effervescence d’innovations – modèles toujours plus puissants (GPT-5, Gemini, Claude, etc.), agents autonomes, intégration dans tous les secteurs – tout en soulevant de vastes questions sociétales et éthiques.
À l’horizon 2030, quel visage pourrait avoir l’IA ? Si les tendances actuelles se poursuivent, on peut esquisser quelques scénarios :
D’un côté, un futur optimiste où l’IA serait devenue un véritable compagnon universel. Nous aurions à nos côtés, au travail comme à la maison, des agents intelligents fiables, nous soulageant des corvées, augmentant notre créativité et veillant à notre bien-être. L’économie connaîtrait un nouvel essor grâce aux gains de productivité et à de nouvelles industries IA. Des problèmes complexes comme la recherche de médicaments, la transition énergétique, l’optimisation des transports pourraient être en partie résolus par l’IA. Les voitures autonomes se généraliseraient, les systèmes de santé prédictifs sauvant des vies en détectant précocement les maladies. Dans ce scénario, l’IA serait un outil apprivoisé : encadré par des lois internationales, aligné sur l’humain, et accepté socialement comme une aide précieuse. Le travail aurait évolué mais dans l’ensemble, on aurait su requalifier la main d’œuvre vers des tâches plus épanouissantes, laissant aux machines les besognes ingrates. Ce serait une décennie 2030 marquée par une prospérité augmentée par l’IA, avec, espérons-le, un usage accru de l’IA pour résoudre les défis planétaires (faim, climat, éducation universelle) et non pour accroître les inégalités.
D’un autre côté, des dérives sont possibles. Si les garde-fous n’avancent pas au même rythme que la technologie, on pourrait imaginer un 2030 plus sombre : une société noyée sous les faux contenus où plus rien n’est fiable en ligne, des travailleurs précarisés par l’automatisation sauvage, une concentration de la richesse chez les quelques entreprises maîtrisant l’IA, et des tensions géopolitiques accrues (course aux armements IA, espionnage algorithmique, etc.). Dans ce monde, l’IA pourrait aussi être source d’aliénation – des humains hyper-dépendants aux assistants automatisés, perdant peu à peu certaines compétences, ou le sens même de leur travail. La promesse d’une IA générale pourrait aussi se retourner en menace si, faute d’alignement, on laissait un système trop puissant prendre des décisions contraires à l’intérêt humain (même sans aller jusqu’à la rébellion de science-fiction, une “boîte noire” super-intelligente mal calibrée pourrait faire de sérieux dégâts économiques ou sociaux).
Entre ces extrêmes, la réalité sera très probablement nuancée. Ce qui paraît certain, c’est que l’IA sera omniprésente en 2030, de manière visible ou invisible. Comme l’électricité ou Internet en leur temps, elle deviendra une infrastructure de base de nos sociétés. La façon dont nous aurons su orienter cette puissance déterminera si elle est globalement bénéfique ou néfaste.
Il nous reste en 2025 quelques années critiques pour façonner l’avenir de l’IA. La tâche n’est pas réservée aux ingénieurs : elle implique les gouvernements, les entreprises, la société civile et chacun d’entre nous. Il faudra du dialogue (entre disciplines, entre nations, entre citoyens) pour définir les limites et les objectifs désirables. L’IA nous confronte en filigrane à des questions sur ce que signifie être humain, sur la place du travail, sur l’organisation de nos sociétés lorsqu’une partie de l’intelligence devient externalisée dans la machine.
En ouvrant ce vaste chantier, peut-être apprendrons-nous aussi sur nous-mêmes. Une chose est sûre : l’histoire de l’IA ne fait que commencer. Et comme le conclut le rapport de Mary Meeker, « seul le temps dira de quel côté de la balance (risques ou gains) pencheront les aspirants actuels de l’IA ». À nous d’écrire la suite avec clairvoyance, pour que l’IA de 2030 soit synonyme de progrès partagé et non de divisions supplémentaires. Le défi est grand, mais l’opportunité l’est tout autant – pour peu que l’humanité se montre à la hauteur de l’intelligence… artificielle qu’elle a créée.
Sources utilisées pour cet article :
LE rapport BOND : https://www.bondcap.com/report/pdf/Trends_Artificial_Intelligence.pdf
Mary Meeker’s 300+ slide deck – summarized by AI https://www.linkedin.com/pulse/mary-meekers-300-slide-deck-summarized-ai-sean-campbell-fqtvc
OpenAI’s ChatGPT surpasses 800 million users; CEO Altman says 10% of world uses it: Report https://economictimes.indiatimes.com/tech/artificial-intelligence/openais-chatgpt-surpasses-800-million-users-ceo-altmansays-10-of-world-uses-it-report/articleshow/120284454.cms?from=mdr
India’s rapid AI adoption, China’s open source lead in focus in Mary Meeker report |
Business News – The Indian Express https://indianexpress.com/article/business/china-india-rapid-ai-adoption-open-source-mary-meeker-report-10043217/
The cost of compute power: A $7 trillion race | McKinsey
https://www.mckinsey.com/industries/technology-media-and-telecommunications/our-insights/the-cost-of-compute-a-7trillion-dollar-race-to-scale-data-centers
It’s not your imagination: AI is speeding up the pace of change | TechCrunch
https://techcrunch.com/2025/05/30/its-not-your-imagination-ai-is-speeding-up-the-pace-of-change/
ChatGPT-5 Rumored for July 2025 Launch – Here’s What to Expect – 9meters https://9meters.com/technology/ai/chatgpt-5-release-date-2
When Will ChatGPT-5 Be Released (May 2025 Info)
https://explodingtopics.com/blog/new-chatgpt-release-date
ChatGPT-5 and GPT-5 rumors: Expected release date, all we know … https://www.androidauthority.com/gpt-5-chatgpt-release-date-rumors-features-3337892/
Google debuts an updated Gemini 2.5 Pro AI model ahead of I/O | TechCrunch
https://techcrunch.com/2025/05/06/google-debuts-an-updated-gemini-2-5-pro-ai-model-ahead-of-i-o/
Claude: Everything you need to know about Anthropic’s AI | TechCrunch
https://techcrunch.com/2025/02/25/claude-everything-you-need-to-know-about-anthropics-ai/
Meet Claude 3.5 Sonnet, Anthropic’s New Model That Beats GPT-4o
https://www.marketingaiinstitute.com/blog/claude-3.5-sonnet
Agentic AI: AutoGPT, BabyAGI, and Autonomous LLM Agents — Substance or Hype? | by
Tech_with_KJ | Apr, 2025 | Medium
https://medium.com/@roseserene/agentic-ai-autogpt-babyagi-and-autonomous-llm-agents-substance-orhype-8fa5a14ee265
AI could replace equivalent of 300 million jobs – report https://www.bbc.com/news/technology-65102150
[PDF] Note de recherche
https://www.ilo.org/sites/default/files/2025-05/BRIEF_French_AI_and_Jobs_2025_19mai_2.pdf
Generative AI could raise global GDP by 7% – Goldman Sachs
https://www.goldmansachs.com/insights/articles/generative-ai-could-raise-global-gdp-by-7-percent
ChatGPT can now see, hear, and speak | OpenAI
https://openai.com/index/chatgpt-can-now-see-hear-and-speak/
US chip export controls are a ‘failure’ because they spur Chinese development, Nvidia boss says | Nvidia | The Guardian
https://www.theguardian.com/technology/2025/may/21/us-chip-export-controls-a-failure-spur-chinese-development-nvidiaboss-says
The EU AI Act: Where Do We Stand in 2025? | Blog – BSR https://www.bsr.org/en/blog/the-eu-ai-act-where-do-we-stand-in-2025
Mary Meeker’s AI Report – by Michael Spencer https://www.ai-supremacy.com/p/mary-meekers-ai-report-bond-2025
Long awaited EU AI Act becomes law after publication in the EU’s …
https://www.whitecase.com/insight-alert/long-awaited-eu-ai-act-becomes-law-after-publication-eus-official-journal
Cet article a été co-écrit par un humain avec o3, DeepResearch et Claude 4 DeepResearch.



7 réflexions sur « Les grandes tendances de l’intelligence artificielle en mai 2025 »