 par
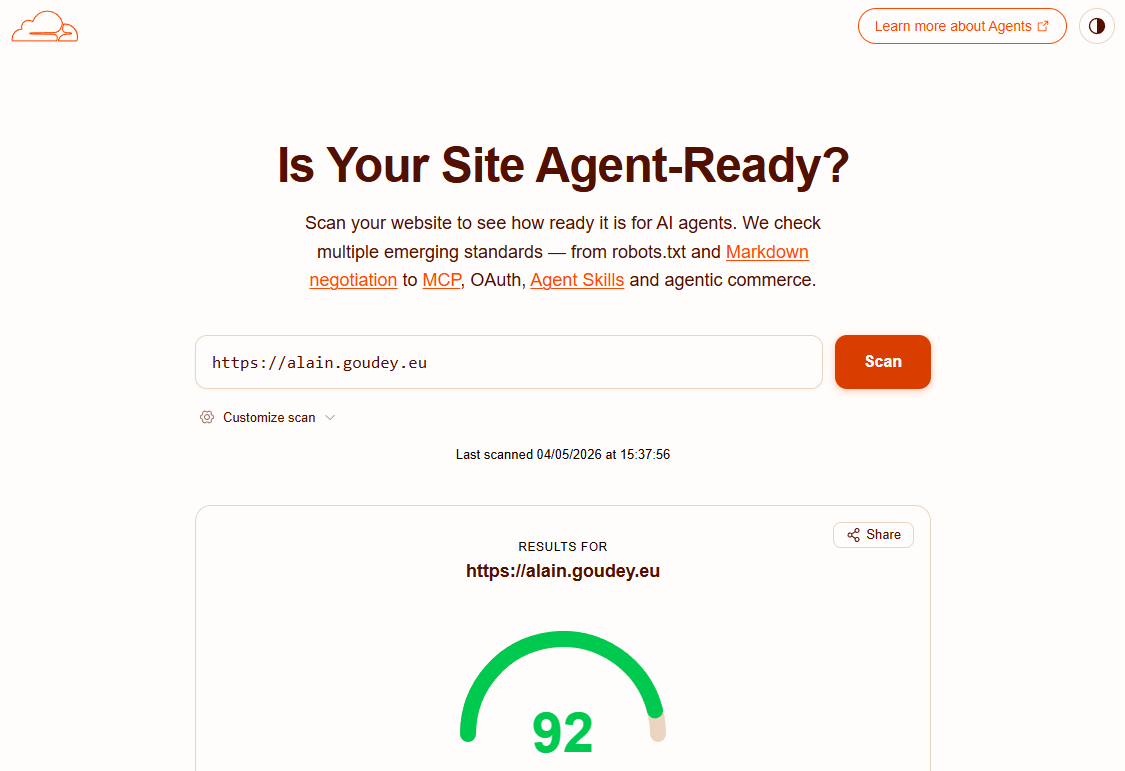
par En avril 2026, Cloudflare a lancé IsItAgentReady, un outil de diagnostic qui évalue la compatibilité d’un site web avec les agents IA. Le principe est simple : entrer une URL, obtenir un score sur 100 et une liste de critères passés ou échoués. Le problème, c’est que la quasi-totalité des sites web actuels obtiennent un score proche de zéro.
J’ai décidé de passer un site statique hébergé sur un mutualisé Apache (OVH) de 0 à 100. Voici le retour d’expérience complet, avec tous les fichiers, les pièges rencontrés, et les solutions qui fonctionnent réellement en production. Comptez une demi-journée de travail si vous êtes à l’aise avec Apache et le terminal, une journée si vous découvrez ces sujets. Et mois si vous maîtrisez bien les outils IA (je suis passé de 25/100 à plus de 90/100 avec Claude Cowork, en 1h environ).
Sommaire
Pourquoi rendre son site Agent-Ready ?
Les moteurs de recherche classiques indexent vos pages depuis 25 ans. Mais une nouvelle génération de clients arrive : les agents IA. ChatGPT, Claude, Perplexity, Copilot et bientôt des milliers d’agents spécialisés parcourent le web pour répondre aux questions de leurs utilisateurs. Ces agents ne lisent pas le HTML comme un navigateur. Ils cherchent des métadonnées structurées, des fichiers descriptifs, des API standardisées.
Un site agent-ready est un site qui dit aux agents : voici qui je suis, ce que je propose, comment accéder à mon contenu, et sous quelles conditions. C’est le SEO de demain, ou plus exactement le GEO (Generative Engine Optimization).
Ce qui change fondamentalement par rapport au SEO classique, c’est la nature de l’interaction. Un bot Google crawle votre page, extrait des mots-clés, et vous classe dans un index. Un agent IA, lui, consomme votre contenu : il le lit, le synthétise, et le reformule dans une réponse à un utilisateur. Il peut aussi agir en votre nom s’il trouve un formulaire de contact ou une API. Les métadonnées que vous exposez ne servent plus seulement à être trouvé, mais à être compris et correctement représenté dans les réponses génératives.
La bonne nouvelle : tout cela est réalisable sur n’importe quel hébergement web, y compris un mutualisé OVH à quelques euros par mois. Aucun framework n’est nécessaire, aucune dépendance Node ou Python. Du HTML, du JSON, un peu de PHP, et un .htaccess bien configuré suffisent.
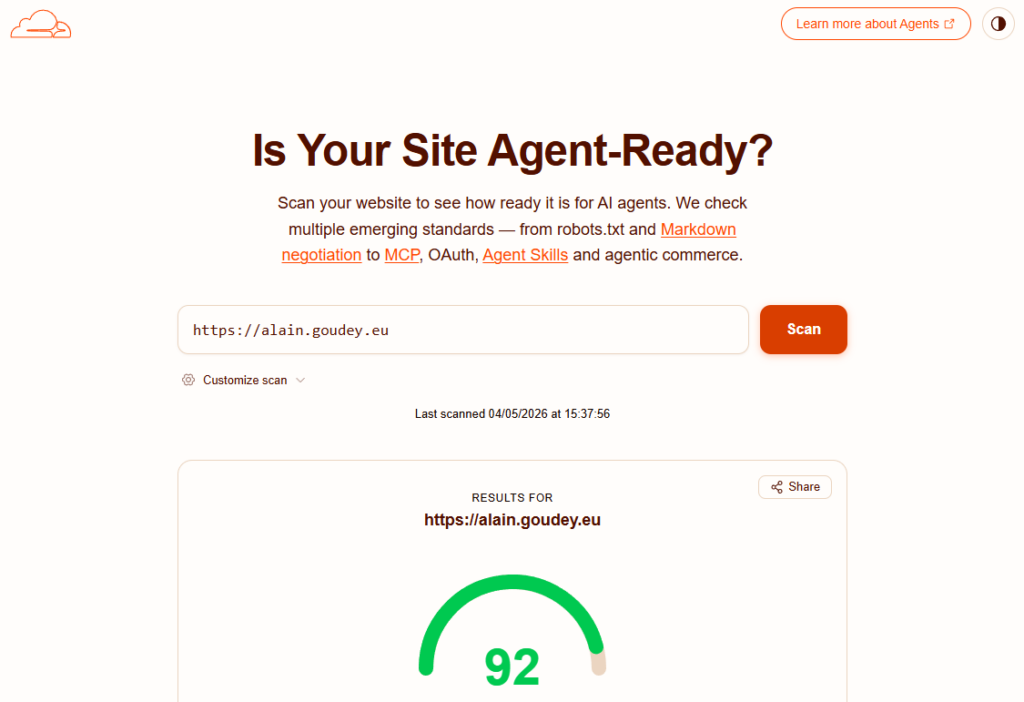
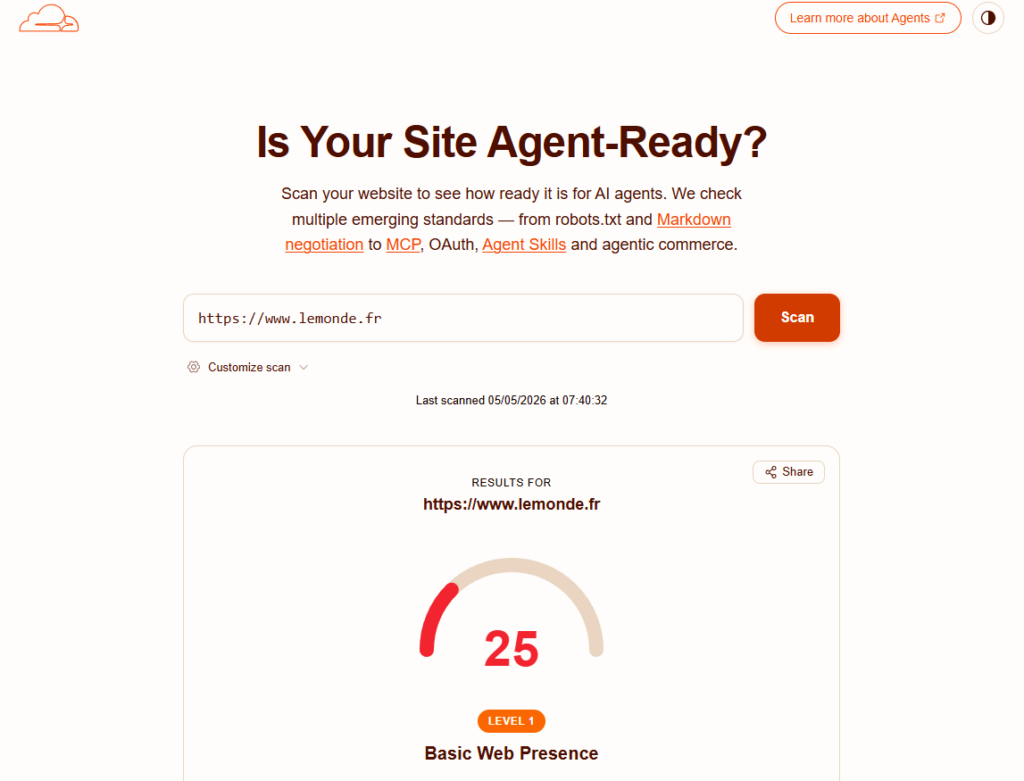
Pour situer l’enjeu : au moment où j’écris ces lignes (mai 2026), la majorité des sites web obtiennent un score inférieur à 10 sur le test IsItAgentReady. Même des sites majeurs (voir ci-dessous lemonde.fr avec un score de 25/100 à la date du 05/05/2026), avec des équipes techniques importantes, n’ont pas encore implémenté ces standards. C’est à la fois un constat et une opportunité : si vous faites le travail maintenant, vous serez dans la poignée de sites qui parlent couramment la langue des agents IA.
Ce que teste exactement IsItAgentReady
L’outil de Cloudflare fonctionne de manière transparente : il envoie des requêtes HTTP à votre site et analyse les réponses. Pour les Link headers, il inspecte les en-têtes de la réponse HTTP de votre page d’accueil. Pour le Content-Signal, il télécharge votre robots.txt et cherche la directive dans un bloc User-agent. Pour le content negotiation Markdown, il envoie une requête avec Accept: text/markdown et vérifie que la réponse contient du Markdown (et non du HTML). Pour les fichiers .well-known, il tente de les télécharger et valide leur structure JSON. Pour WebMCP, il analyse le HTML de votre page d’accueil à la recherche d’un script qui appelle navigator.modelContext.provideContext() ou expose window.__webmcp_tools.
Chaque critère vaut environ 11 points. Un score de 92 signifie que 8 critères sur 9 sont validés. Le test est binaire par critère : il passe ou il échoue, il n’y a pas de score partiel. Cela signifie qu’une erreur de syntaxe JSON dans un seul fichier vous coûte 11 points d’un coup. C’est à la fois frustrant (pas de gratification progressive) et motivant (chaque fichier corrigé fait bondir le score). J’ai toutefois constaté un souci car mon robots.txt est une ancienne version qui ne se met pas à jour dans le test cloudflare en dépit de mes modifications sur le site. Théoriquement je devrai être à 100/100.
L’outil est accessible gratuitement sur isitagentready.com. Entrez votre URL, cliquez sur « Scan », et en quelques secondes vous obtenez un diagnostic complet avec, pour chaque critère, un statut vert (passé) ou rouge (échoué) et un lien vers la documentation correspondante.
Prérequis avant de commencer pour aller vers un site agent-ready
Avant de se lancer, assurez-vous d’avoir un fichier llms.txt à la racine de votre site. Ce fichier, popularisé par le standard llmstxt.org, est une description structurée de votre site destinée aux LLM. Il n’est pas directement noté par IsItAgentReady, mais il est référencé par quatre des neuf critères (Link headers, API Catalog, MCP Server Card, Agent Skills). C’est le socle informationnel de toute la démarche.
Un bon llms.txt contient : une présentation synthétique du site et de son auteur, les thématiques couvertes, les pages clés avec leurs URLs, et les informations de contact. Rédigez-le comme si vous deviez briefer un assistant IA en 60 secondes sur qui vous êtes et ce qu’on trouve sur votre site.
Vous aurez aussi besoin d’un accès FTP ou SSH à votre hébergement, de PHP disponible (même sur un mutualisé basique, c’est le cas), et d’un terminal avec curl pour tester vos modifications. Un éditeur de texte avec coloration JSON est un plus appréciable vu le nombre de fichiers JSON à créer.
Les 9 critères du test IsItAgentReady
L’outil de Cloudflare évalue 9 signaux, chacun valant environ 11 points. Voici chacun d’entre eux avec l’implémentation concrète qui m’a permis de les valider.
1. Link Response Headers (RFC 8288)
Le premier critère vérifie que votre serveur envoie des en-têtes HTTP Link pour guider les agents vers les ressources de découverte du site. C’est l’équivalent d’un panneau indicateur à l’entrée : « le plan du site est par ici, la documentation est par là ».
Ce qu’il faut envoyer :
Link: </.well-known/api-catalog>; rel="api-catalog"
Link: </llms.txt>; rel="service-doc"
Link: </.well-known/agent-skills/index.json>; rel="describedby"Le piège Apache/OVH : sur un hébergement mutualisé, les directives Header set ou Header append dans le .htaccess ne fonctionnent pas toujours, même avec mod_headers activé. J’ai perdu du temps à tester différentes syntaxes (<Files>, SetEnvIf, Header always append) sans succès.
La solution qui fonctionne : passer par PHP. Créez un fichier index.php à la racine :
<?php
header('Link: </.well-known/api-catalog>; rel="api-catalog"', false);
header('Link: </llms.txt>; rel="service-doc"', false);
header('Link: </.well-known/agent-skills/index.json>; rel="describedby"', false);
readfile(__DIR__ . '/index.html');
Le paramètre false dans header() est crucial : il permet d’envoyer plusieurs en-têtes Link sans que chaque appel écrase le précédent. Ensuite, ajoutez dans votre .htaccess :
DirectoryIndex index.php index.htmlAinsi, Apache servira index.php en priorité, qui injectera les en-têtes puis affichera votre index.html normalement. Du point de vue du visiteur, rien ne change : le contenu HTML est identique, le temps de chargement reste le même. Seuls les en-têtes HTTP sont enrichis.
Vérifiez avec les DevTools du navigateur (onglet Network > cliquez sur la requête vers / > onglet Headers) que les trois en-têtes Link apparaissent bien dans la section « Response Headers ». Vous pouvez aussi utiliser curl -I https://votre-site.fr/ depuis le terminal.
Pourquoi trois en-têtes Link ? Chacun pointe vers un type de ressource différent. Le rel="api-catalog" dit aux agents « voici le catalogue de mes API » (RFC 9727). Le rel="service-doc" dit « voici ma documentation principale » (dans notre cas, le llms.txt). Le rel="describedby" dit « voici une description structurée de mes capacités » (le fichier Agent Skills). Ensemble, ces trois en-têtes forment un trio de découverte qui permet à n’importe quel agent de comprendre votre site dès la première requête HTTP, avant même de parser le HTML.
Variante Nginx : si vous êtes sur Nginx au lieu d’Apache, ajoutez directement dans votre bloc server :
add_header Link '</.well-known/api-catalog>; rel="api-catalog"' always;
add_header Link '</llms.txt>; rel="service-doc"' always;
add_header Link '</.well-known/agent-skills/index.json>; rel="describedby"' always;Variante Node.js / Express : si votre site tourne sous Express, ajoutez un middleware :
app.use((req, res, next) => {
res.append('Link', '</.well-known/api-catalog>; rel="api-catalog"');
res.append('Link', '</llms.txt>; rel="service-doc"');
res.append('Link', '</.well-known/agent-skills/index.json>; rel="describedby"');
next();
});2. Markdown pour les Agents (Content Negotiation)
L’idée est simple : quand un agent envoie Accept: text/markdown dans sa requête HTTP, votre serveur lui sert une version Markdown de la page au lieu du HTML. L’agent obtient ainsi du contenu propre, sans balisage, facile à traiter.
Implémentation : créez un dossier /md/ à la racine contenant une version .md de chaque page. Par exemple, /md/index.md, /md/contact.md, /md/expertise.md, etc.
Ajoutez ensuite ces règles dans votre .htaccess :
# Content negotiation - Markdown pour agents
<IfModule mod_rewrite.c>
RewriteCond %{HTTP_ACCEPT} text/markdown
RewriteCond %{REQUEST_FILENAME} !-d
RewriteCond %{DOCUMENT_ROOT}/md%{REQUEST_URI}.md -f
RewriteRule ^(.*)$ /md/$1.md [L]
RewriteCond %{HTTP_ACCEPT} text/markdown
RewriteRule ^/?$ /md/index.md [L]
</IfModule>
<IfModule mod_headers.c>
<FilesMatch "\.md$">
Header set Content-Type "text/markdown; charset=utf-8"
</FilesMatch>
</IfModule>La première règle gère les pages internes (/expertise → /md/expertise.md), la seconde gère la page d’accueil. Vous pouvez tester avec curl :
curl -H "Accept: text/markdown" https://votre-site.fr/expertiseConseil : pour le fichier /md/index.md, vous pouvez réutiliser le contenu de votre llms.txt si vous en avez un. Les deux remplissent une fonction similaire.
Sur le contenu des fichiers Markdown : ne vous contentez pas d’un export brut du HTML vers Markdown. Profitez-en pour structurer le contenu de manière optimale pour un LLM : des en-têtes clairs, des listes à puces pour les faits clés, des métadonnées en début de fichier (nom, titre, institution, contact). Un agent qui reçoit du Markdown bien structuré produira des réponses beaucoup plus précises qu’avec du HTML parsé approximativement.
3. Content Signals dans robots.txt
Les Content Signals sont une extension du robots.txt (proposition IETF en cours via contentsignals.org) qui permet d’exprimer des préférences granulaires sur l’utilisation de votre contenu par les IA : entraînement autorisé ou non, recherche autorisée, utilisation en entrée de prompt, etc.
Le piège : la directive Content-Signal doit impérativement se trouver à l’intérieur d’un bloc User-agent, et non pas flottante en fin de fichier. C’est la subtilité qui m’a coûté plusieurs tentatives.
Format correct : placez ceci en tout début de votre robots.txt, avant les autres blocs User-agent :
# Content Signals (AI preferences)
User-agent: *
Content-Signal: ai-train=no, search=yes, ai-input=noIci, ai-train=no signifie que vous n’autorisez pas l’utilisation de votre contenu pour entraîner des modèles, search=yes autorise l’indexation pour la recherche (y compris IA), et ai-input=no interdit l’injection de votre contenu comme entrée de prompt. Adaptez ces valeurs selon votre politique.
Important : le bloc Content-Signal doit être rattaché à un User-agent: * et non isolé. Le parseur de l’outil Cloudflare ne le détectera pas autrement.
Valeurs possibles : les signaux reconnus incluent ai-train (entraînement de modèles), search (indexation pour la recherche), ai-input (utilisation comme contexte de prompt), et ai-summarize (résumé automatique). Chacun accepte yes ou no. Vous pouvez les combiner sur une seule ligne séparée par des virgules, ou les déclarer sur des lignes séparées. La syntaxe sur une seule ligne est plus compacte et fonctionne bien avec le parseur Cloudflare.
4. API Catalog (RFC 9727)
Le fichier /.well-known/api-catalog est un standard W3C/IETF qui recense les API et services exposés par un site. Même un site statique sans API au sens strict peut l’implémenter en référençant ses points d’entrée informationnels.
Créez le fichier /.well-known/api-catalog (sans extension) avec le type MIME application/linkset+json :
{
"linkset": [
{
"anchor": "https://votre-site.fr/",
"service-desc": [
{
"href": "https://votre-site.fr/llms.txt",
"type": "text/plain"
}
],
"service-doc": [
{
"href": "https://votre-site.fr/llms.txt",
"type": "text/plain"
}
],
"status": [
{
"href": "https://votre-site.fr/",
"type": "text/html"
}
]
}
]
}Et dans votre .htaccess, assurez-vous que le type MIME est correctement déclaré :
<IfModule mod_mime.c>
AddType application/linkset+json api-catalog
</IfModule>Pour aller plus loin : si votre site expose une vraie API REST (un endpoint de recherche, un flux RSS structuré, etc.), ajoutez-la comme entrée supplémentaire dans le linkset. Le standard RFC 9727 est conçu pour référencer plusieurs services : chaque objet du tableau linkset peut avoir son propre anchor et ses propres relations. Pour un site statique, une seule entrée suffit.
5. OAuth / OpenID Connect Discovery
Ce critère vérifie l’existence du fichier /.well-known/openid-configuration. Pour un site public sans authentification, il suffit de créer un fichier minimal qui indique que le contenu est librement accessible :
{
"issuer": "https://votre-site.fr",
"authorization_endpoint": "https://votre-site.fr/contact",
"token_endpoint": "https://votre-site.fr/contact",
"response_types_supported": ["code"],
"grant_types_supported": ["authorization_code"],
"subject_types_supported": ["public"],
"id_token_signing_alg_values_supported": ["RS256"],
"scopes_supported": ["openid", "profile"],
"service_documentation": "https://votre-site.fr/llms.txt",
"x-note": "Site public sans API protegee. Ce fichier est fourni pour la conformite agent discovery uniquement."
}Le champ x-note est une convention (préfixe x-) pour indiquer aux développeurs et aux agents que ce fichier est purement déclaratif. Un agent bien conçu comprendra qu’il n’y a pas d’authentification à négocier ici.
Pourquoi l’inclure si on n’a pas d’API ? Parce que l’absence du fichier est interprétée comme un signal négatif par le test Cloudflare. Sa présence, même minimale, indique que vous avez réfléchi à la question de l’authentification et que vous avez choisi de rendre votre contenu librement accessible. C’est de la communication intentionnelle.
6. OAuth Protected Resource Metadata (RFC 9728)
Même logique : le fichier /.well-known/oauth-protected-resource déclare les ressources protégées par OAuth. Pour un site entièrement public, on indique simplement que tout est accessible en lecture sans authentification :
{
"resource": "https://votre-site.fr",
"authorization_servers": ["https://votre-site.fr"],
"scopes_supported": ["read"],
"x-note": "Site public. Tout le contenu est accessible sans authentification."
}7. MCP Server Card
Le Model Context Protocol (MCP) est un standard émergent qui permet aux agents IA de découvrir et d’interagir avec des services. Le « Server Card » est la carte de visite MCP de votre site. Ce fichier se place dans /.well-known/mcp/server-card.json :
{
"serverInfo": {
"name": "mon-site",
"version": "1.0.0",
"description": "Description concise de votre site et de son contenu principal."
},
"transport": {
"type": "https",
"url": "https://votre-site.fr"
},
"capabilities": {
"resources": true,
"tools": false,
"prompts": false
},
"resources": [
{
"name": "llms-txt",
"description": "Informations structurees pour les LLMs",
"uri": "https://votre-site.fr/llms.txt",
"mimeType": "text/plain"
},
{
"name": "sitemap",
"description": "Plan du site XML",
"uri": "https://votre-site.fr/sitemap.xml",
"mimeType": "application/xml"
}
]
}Déclarez "tools": false et "prompts": false si votre site est purement informationnel (pas d’API REST, pas de fonction callable). Si vous avez un formulaire de contact, vous pouvez choisir de ne pas l’exposer comme « tool » MCP pour éviter le spam automatisé. Listez dans resources les fichiers clés que les agents devraient connaître en priorité.
Note sur la spécification : la MCP Server Card est définie dans le SEP-1649 du Model Context Protocol. Le standard est encore jeune et susceptible d’évoluer, mais le chemin /.well-known/mcp/server-card.json est déjà reconnu par plusieurs scanners et agents.
8. Agent Skills Discovery
Le standard Agent Skills (agentskills.io, v0.2.0) permet de décrire les « compétences » de votre site : quelles informations un agent peut-il y trouver, quelles actions peut-il y effectuer ? Le fichier se place dans /.well-known/agent-skills/index.json :
{
"$schema": "https://agentskills.io/schema/v0.2.0/index.json",
"skills": [
{
"name": "get-biography",
"type": "resource",
"description": "Retrieve structured biographical information.",
"url": "https://votre-site.fr/llms.txt",
"sha256": "abc123..."
},
{
"name": "browse-publications",
"type": "resource",
"description": "Browse academic publications.",
"url": "https://votre-site.fr/publications",
"sha256": "def456..."
},
{
"name": "contact-form",
"type": "action",
"description": "Submit a contact request via the form.",
"url": "https://votre-site.fr/contact",
"sha256": "ghi789..."
}
]
}Chaque skill a un type (resource pour du contenu consultable, action pour un formulaire ou une interaction) et un hash SHA-256 du fichier référencé, qui permet aux agents de vérifier l’intégrité du contenu. Pour calculer le hash :
sha256sum votre-fichier.htmlPensez à mettre à jour les hash chaque fois que vous modifiez les fichiers référencés.
Combien de skills déclarer ? Il n’y a pas de minimum ni de maximum, mais visez la pertinence. Chaque skill doit correspondre à une action ou une ressource réellement utile pour un agent. Un site vitrine peut en avoir 3 à 5 (biographie, publications, portfolio, contact). Un site e-commerce pourrait en avoir davantage (catalogue produits, suivi commande, politique retour, etc.). L’important est que la description soit suffisamment précise pour qu’un agent sache quand utiliser chaque skill.
9. WebMCP (Browser API)
WebMCP est le critère le plus avant-gardiste. Il s’agit d’exposer des « outils » directement dans le navigateur via l’API JavaScript navigator.modelContext.provideContext(). Quand un agent IA navigue sur votre site via un navigateur (comme le font déjà Claude, ChatGPT avec browsing, ou Perplexity), il peut appeler ces outils pour obtenir des données structurées.
Créez un fichier /js/webmcp.js :
(function() {
'use strict';
if (typeof navigator === 'undefined') return;
var tools = [
{
name: "get_site_info",
description: "Get structured information about this website.",
inputSchema: {
type: "object",
properties: {},
required: []
},
execute: function() {
return fetch('/llms.txt')
.then(function(r) { return r.text(); })
.then(function(text) { return { content: text }; });
}
},
{
name: "get_contact_info",
description: "Get contact information.",
inputSchema: {
type: "object",
properties: {},
required: []
},
execute: function() {
return Promise.resolve({
contact_url: "https://votre-site.fr/contact",
response_time: "48-72 heures"
});
}
}
];
if (navigator.modelContext &&
typeof navigator.modelContext.provideContext === 'function') {
navigator.modelContext.provideContext({ tools: tools });
}
window.__webmcp_tools = tools;
})();Incluez ensuite ce script dans toutes vos pages HTML :
<script src="/js/webmcp.js" defer></script>L’API navigator.modelContext n’est pas encore supportée par les navigateurs grand public, mais elle est déjà utilisée par les agents qui naviguent via des navigateurs instrumentés (Playwright, Puppeteer, ou les modes « browsing » des LLM). Le script se dégrade gracieusement : si l’API n’existe pas, il ne fait rien. L’exposer sur window.__webmcp_tools en fallback permet aux agents qui ne supportent pas l’API native de découvrir les outils via le DOM.
Quels outils déclarer ? Pensez à ce qu’un agent pourrait vouloir savoir sur votre site sans parser le HTML : informations de contact, thématiques principales, catalogue de services. Chaque outil a un inputSchema (JSON Schema décrivant les paramètres attendus) et une fonction execute qui retourne une Promise. Gardez les outils simples et sans effets de bord pour les types resource.
La structure de fichiers complète d’un site agent-ready
Au final, voici les fichiers ajoutés ou modifiés pour un site statique Apache :
/
├── .htaccess (modifie)
├── index.php (nouveau)
├── index.html (inchange)
├── robots.txt (modifie)
├── llms.txt (recommande, meme si non note)
├── js/
│ └── webmcp.js (nouveau)
├── md/
│ ├── index.md (nouveau)
│ ├── contact.md (nouveau)
│ └── ... (une version .md par page)
└── .well-known/
├── api-catalog (nouveau)
├── openid-configuration (nouveau)
├── oauth-protected-resource (nouveau)
├── mcp/
│ └── server-card.json (nouveau)
└── agent-skills/
└── index.json (nouveau)Le .htaccess complet (sections ajoutées)
Voici les blocs à ajouter à votre .htaccess existant. L’ensemble est compatible avec un hébergement mutualisé Apache standard :
# Priorite index.php pour les Link headers
DirectoryIndex index.php index.html
# Content negotiation - Markdown pour agents
<IfModule mod_rewrite.c>
RewriteCond %{HTTP_ACCEPT} text/markdown
RewriteCond %{REQUEST_FILENAME} !-d
RewriteCond %{DOCUMENT_ROOT}/md%{REQUEST_URI}.md -f
RewriteRule ^(.*)$ /md/$1.md [L]
RewriteCond %{HTTP_ACCEPT} text/markdown
RewriteRule ^/?$ /md/index.md [L]
</IfModule>
<IfModule mod_headers.c>
<FilesMatch "\.md$">
Header set Content-Type "text/markdown; charset=utf-8"
</FilesMatch>
</IfModule>
# Types MIME pour .well-known
<IfModule mod_mime.c>
AddType application/linkset+json api-catalog
</IfModule>
<IfModule mod_headers.c>
<Files "api-catalog">
Header set Content-Type "application/linkset+json"
</Files>
<Files "openid-configuration">
Header set Content-Type "application/json"
</Files>
<Files "oauth-protected-resource">
Header set Content-Type "application/json"
</Files>
</IfModule>
# CORS pour les fichiers de decouverte
<FilesMatch "\.(txt|xml|jsonld|json)$">
Header set Access-Control-Allow-Origin "*"
</FilesMatch>Les pièges rencontrés (et comment les éviter) pour un site agent-ready
1. Les en-têtes Link qui ne s’envoient pas. Certain hébergeurs mutualisés, mod_headers dans .htaccess ne permet pas toujours d’ajouter des en-têtes personnalisés. La solution PHP avec index.php est la plus fiable et la plus portable. Si vous êtes sur Nginx, utilisez add_header dans votre bloc server.
2. Le Content-Signal mal positionné. La directive Content-Signal doit être à l’intérieur d’un bloc User-agent: *, pas flottante en fin de fichier. Le parseur de l’outil Cloudflare applique la spécification à la lettre : une directive orpheline est ignorée.
3. Le cache de l’outil Cloudflare. IsItAgentReady met en cache les résultats. Si vous corrigez un fichier et relancez le test immédiatement, vous verrez peut-être encore l’ancienne version. L’outil utilise le CDN de Cloudflare pour récupérer vos fichiers, et si vous êtes vous-même derrière Cloudflare, la propagation peut prendre du temps. Pensez à purger le cache depuis votre dashboard Cloudflare, ou attendez quelques heures. Vous pouvez aussi tenter un appel direct à l’endpoint API du scanner pour forcer un nouveau scan.
4. Le dossier .well-known sur mutualisé. Certains hébergeurs bloquent l’accès aux dossiers commençant par un point. Vérifiez que votre .htaccess n’a pas de règle RedirectMatch 403 /\. trop agressive, et testez l’accès avec curl https://votre-site.fr/.well-known/api-catalog.
5. Les URLs propres et le content negotiation. Si vous utilisez des URLs sans extension (/expertise au lieu de /expertise.html), vos règles de réécriture Markdown doivent en tenir compte. La condition RewriteCond %{DOCUMENT_ROOT}/md%{REQUEST_URI}.md -f gère ce cas en vérifiant que le fichier .md correspondant existe avant de réécrire. Mais testez chaque page individuellement avec curl -H "Accept: text/markdown" car les interactions entre règles de réécriture peuvent être surprenantes.
6. L’ordre des règles dans .htaccess. Les règles de content negotiation Markdown doivent être placées après vos règles de suppression d’extension (.html) mais avant la réécriture interne qui ajoute .html. Si l’ordre est inversé, Apache peut réécrire l’URL en .html avant même que la condition text/markdown soit évaluée, et votre content negotiation ne fonctionnera jamais. Pour déboguer, activez temporairement le RewriteLog si votre hébergeur le permet.
7. Les fichiers sans extension dans .well-known. Le fichier api-catalog (sans extension .json) peut poser problème. Certains serveurs ne savent pas quel type MIME servir pour un fichier sans extension. C’est pourquoi la directive AddType application/linkset+json api-catalog et le Header set Content-Type dans une balise <Files> sont tous les deux nécessaires : l’un est un filet de sécurité pour l’autre.
8. Les hash SHA-256 qui changent. Dans le fichier Agent Skills, chaque ressource référencée a un hash SHA-256. Si vous modifiez une page (même un espace en trop), le hash change et l’intégrité échoue. En pratique, les agents ne vérifient pas encore systématiquement ces hash, mais c’est une bonne hygiène de les maintenir à jour. Intégrez le recalcul dans votre workflow de déploiement : un simple sha256sum *.html avant chaque mise en production.
Vérification et débogage du site agent-ready
Avant de lancer le test Cloudflare, vérifiez chaque critère individuellement :
# 1. Link headers
curl -I https://votre-site.fr/ | grep -i "link:"
# 2. Markdown content negotiation
curl -H "Accept: text/markdown" https://votre-site.fr/
# 3. Content-Signal dans robots.txt
curl https://votre-site.fr/robots.txt | head -5
# 4. API Catalog
curl https://votre-site.fr/.well-known/api-catalog
# 5. OpenID Configuration
curl https://votre-site.fr/.well-known/openid-configuration
# 6. OAuth Protected Resource
curl https://votre-site.fr/.well-known/oauth-protected-resource
# 7. MCP Server Card
curl https://votre-site.fr/.well-known/mcp/server-card.json
# 8. Agent Skills
curl https://votre-site.fr/.well-known/agent-skills/index.json
# 9. WebMCP (verifier dans le source HTML)
curl https://votre-site.fr/ | grep "webmcp"Si toutes ces commandes retournent le contenu attendu, vous êtes prêt pour le test.
Script de vérification automatisé : pour gagner du temps, vous pouvez regrouper ces commandes dans un script bash. Ajoutez des tests de code retour HTTP (curl -o /dev/null -s -w "%{http_code}") pour vérifier que chaque endpoint retourne un 200, et parsez le Content-Type pour confirmer qu’il correspond au type attendu. Un jq . sur les fichiers JSON vous permettra aussi de détecter les erreurs de syntaxe avant que le scanner Cloudflare ne les voie.
Au-delà du score : pourquoi c’est important un site agent-ready ?
Obtenir 90 ou 100 sur IsItAgentReady n’est pas une fin en soi. C’est un indicateur que votre site parle la langue des agents IA, et cela a des implications concrètes.
D’abord, la visibilité dans les réponses générées par IA. Quand un utilisateur demande à ChatGPT, Claude ou Perplexity des informations sur votre domaine d’expertise, un site correctement balisé a plus de chances d’être cité comme source. Le fichier llms.txt, les métadonnées structurées et les Content Signals indiquent aux agents que votre contenu est fiable, à jour et que vous consentez explicitement à son utilisation en contexte de recherche. C’est une forme de recommandation technique : vous facilitez le travail de l’agent, et en retour il vous cite plus facilement et plus fidèlement.
Ensuite, le contrôle. Les Content Signals vous permettent de dire explicitement « oui » à l’indexation pour la recherche tout en disant « non » à l’entraînement des modèles. C’est un levier de gouvernance qui n’existait pas jusqu’ici. Contrairement au robots.txt classique qui ne permet que d’autoriser ou de bloquer le crawl, les Content Signals expriment des nuances : vous pouvez autoriser la recherche mais interdire l’entraînement, autoriser le résumé mais interdire l’injection dans un prompt. C’est un vocabulaire de consentement bien plus riche.
Enfin, la préparation. Ces standards sont jeunes (certains encore en draft IETF) mais convergent rapidement. MCP est poussé par Anthropic et adopté par un écosystème croissant, WebMCP émerge de la communauté des agents navigateurs, les Content Signals sont portés par une coalition multi-acteurs incluant des éditeurs et des développeurs d’IA. Implémenter ces standards aujourd’hui, c’est ne pas avoir à rattraper un retard demain.
Feuille de route du site agent-ready : par où commencer ?
Si vous partez de zéro, voici l’ordre que je recommande :
Phase 1 (30 minutes) : créez votre llms.txt et ajoutez le Content-Signal dans votre robots.txt. Ce sont les deux actions les plus rapides et les plus impactantes. Le llms.txt est déjà lu par de nombreux agents même sans les autres standards.
Phase 2 (1 heure) : mettez en place les fichiers .well-known (api-catalog, openid-configuration, oauth-protected-resource, mcp/server-card.json, agent-skills/index.json). Ce sont des fichiers JSON statiques à déposer sur votre serveur. Le plus long est de rédiger les descriptions et de calculer les hash SHA-256.
Phase 3 (1 heure) : implémentez les Link headers (via index.php sur Apache) et le content negotiation Markdown. Ces deux critères nécessitent de toucher à la configuration serveur, ce qui demande un peu plus d’attention et de tests.
Phase 4 (30 minutes) : ajoutez le script WebMCP dans vos pages HTML. C’est le critère le plus « futuriste » et le moins critique à court terme, mais il complète le tableau pour atteindre 100. C’est aussi le seul critère qui demande d’écrire du JavaScript, mais le code nécessaire reste minimal.
Entre chaque phase, testez avec curl et les DevTools avant de relancer le test Cloudflare. Et surtout, gardez en tête que le cache de l’outil peut vous jouer des tours : si un critère échoue alors que votre curl retourne le bon résultat, attendez quelques heures avant de tout remettre en question.
Adapter la démarche du site agent-ready selon votre stack technique
L’exemple détaillé dans cet article concerne un site statique HTML sur Apache mutualisé, mais les principes s’appliquent à toutes les stacks.
WordPress : la gestion des en-têtes Link peut se faire via un petit plugin custom ou dans le functions.php de votre thème enfant avec add_action('send_headers', ...). Les fichiers .well-known doivent être créés physiquement à la racine (WordPress ne les gère pas nativement). Pour le content negotiation Markdown, vous pouvez utiliser un plugin qui intercepte les requêtes avec Accept: text/markdown et retourne une version simplifiée du contenu via wp_strip_all_tags() avec une mise en forme Markdown basique. Le script WebMCP s’ajoute classiquement avec wp_enqueue_script().
Sites statiques (Hugo, Jekyll, Eleventy) : c’est paradoxalement le cas le plus simple. Générez les fichiers .well-known et les versions Markdown comme des fichiers statiques supplémentaires dans votre pipeline de build. Pour les Link headers, si vous déployez sur Netlify ou Vercel, utilisez le fichier _headers (Netlify) ou vercel.json (Vercel) pour injecter les en-têtes. Sur Cloudflare Pages, utilisez _headers également. Pour le content negotiation, Netlify et Cloudflare Pages supportent les Edge Functions qui peuvent intercepter l’en-tête Accept.
Applications SPA (React, Vue, Angular) : le défi principal est que les agents n’exécutent pas toujours le JavaScript. Assurez-vous que vos fichiers .well-known et votre robots.txt sont servis statiquement par le serveur (et non générés par le framework). Le script WebMCP fonctionne naturellement dans une SPA puisqu’il s’exécute côté client. Pour le content negotiation Markdown, configurez votre serveur de production (Nginx, Caddy, etc.) pour gérer la réécriture au niveau serveur, pas au niveau application.
Et le llms.txt dans tout ça ? C’est important pour un site agent-ready ?
Le fichier llms.txt n’est pas directement évalué par IsItAgentReady, mais il est le fil rouge de toute l’architecture agent-ready. Il est référencé dans les Link headers (rel="service-doc"), dans l’API Catalog (service-desc et service-doc), dans le MCP Server Card (comme ressource), dans l’Agent Skills (comme skill get-biography), et même dans le openid-configuration (service_documentation).
C’est votre page d’accueil pour les machines. Si vous ne deviez implémenter qu’une seule chose avant de toucher aux 9 critères Cloudflare, ce serait ce fichier. Un llms.txt bien rédigé peut à lui seul améliorer significativement la façon dont les IA parlent de vous et de votre activité. Pensez-y comme un pitch deck pour algorithmes : clair, factuel, structuré, et facilement parsable.
Le format recommandé par llmstxt.org est du Markdown simple avec des en-têtes hiérarchiques. Commencez par un titre # Nom du site, suivi d’un paragraphe de présentation, puis des sections pour chaque aspect important (expertise, publications, services, contact). Incluez les URLs complètes de vos pages clés. Un agent qui lit ce fichier doit pouvoir répondre correctement à la question « qui est cette personne / entreprise et que fait-elle ? » sans avoir à crawler le reste du site.
Ressources et références
Voici les spécifications et outils mentionnés dans cet article :
- IsItAgentReady par Cloudflare (l’outil de test)
- RFC 8288 (Web Linking)
- RFC 9727 (API Catalog)
- RFC 9728 (OAuth Protected Resource Metadata)
- Content Signals
- Agent Skills Discovery
- Model Context Protocol (MCP)
- llms.txt
Le web des agents IA est en train de se construire. Les standards décrits ici ne sont pas des gadgets : ce sont les fondations d’un nouveau contrat entre les éditeurs de contenu et les machines qui le consomment. Un contrat dans lequel vous gardez le contrôle sur ce qui est autorisé et ce qui ne l’est pas, tout en maximisant votre visibilité dans les nouveaux canaux de découverte.
Que vous gériez un site personnel, un blog technique, un site institutionnel ou un e-commerce, la démarche est la même. Les fichiers sont simples, les standards sont ouverts, et le test Cloudflare vous donne un retour immédiat sur votre progression.
Une dernière réflexion : le site agent-ready ne remplace pas le SEO classique, il le complète. Vos balises title, vos meta descriptions, votre Schema.org, votre maillage interne et votre contenu de qualité restent essentiels pour les moteurs de recherche traditionnels. Les standards décrits ici ajoutent une couche de métadonnées structurées spécifiquement conçue pour les machines qui raisonnent, et non plus seulement pour celles qui indexent. C’est la différence entre être dans un annuaire et savoir se présenter de manière intelligible à quelqu’un qui vous rencontre pour la première fois.
Le mouvement est lancé, et il est irréversible. Les sites qui s’adaptent tôt bénéficieront d’un avantage durable : celui d’être compris, cités et recommandés par la prochaine génération d’interfaces entre les humains et l’information. C’est ça être un site agent-ready.
Alors testez votre site sur IsItAgentReady.com… le mien est à 92/100 aujourd’hui


