 par
par LUCIE, IA générative française véritablement open source (au même titre que Bloom, Croissant ou Pleias 3B), a été officiellement lancée le 22 janvier 2025 lors du Paris Open Source AI Summit. Cette innovation majeure est le fruit d’une collaboration entre Linagora et le consortium OpenLLM France, financé par un projet France 2030 autour des communs numériques pour l’IA générative.
La journée du 25 janvier 2025, suite à un post X d’Eduscol (en date du 23/01 à 7h du matin) a vu la page du projet fermer en raison des mauvais résultats aux différents tests opérés par les internautes. J’avais personnellement rapidement testé LUCIE le jour de son lancement le 22/01 et en effet, le modèle n’était clairement pas prêt à une ouverture grand public.
Bien que n’étant pas partie prenante dans ce projet, voici une analyse de la situation autour de ce lancement pour inspirer tous les projets de transformation par l’IA d’un secteur donné. En résumé ? Il ne faut pas brûler les étapes.
LUCIE, c’est quoi ? Une architecture robuste pour un projet open source souverain
LUCIE est un modèle de langage de 6,71 milliards de paramètres, inspiré de l’architecture Llama 3.1. Son entraînement, réalisé sur le supercalculateur Jean Zay du GENCI, a nécessité 512 GPU Nvidia H100 pendant 550 000 heures [2]. Le modèle a été entraîné sur un corpus de 3 000 milliards de tokens, avec une répartition linguistique équilibrée : 30% en français, 30% en anglais, 20% de code et mathématiques, et le reste en allemand, espagnol et italien [7].
Lucie se distingue autour de trois dimensions fortes :
- Des données d’entraînement accessibles sous licence publique
- Des algorithmes et méthodes d’entraînement entièrement documentés
- Un modèle disponible sous licence Apache 2.0
On ne va pas débattre ici de l’architecture, ce n’est pas mon sujet. La vision qui sous tend le projet est bonne : réellement open source, poids open source, dataset open source, transparence des méthodes, des algorithmes, et une volonté de « faire quelque chose » face aux offres internationales.
Quels ont été les problèmes du lancement de LUCIE ? Tout a généré de la frustration !
L’accès à la plateforme lucie.chat permettait d’interagir avec ce modèle. Un design épuré, un logo bien réussi et des ambitions affichées clairement, cela partait bien. On pouvait lire : « Que ce soit pour l’éducation, le gouvernement ou la recherche, Lucie est conçue pour être un modèle sur lequel vous pouvez compter. »

Des problèmes techniques et de qualité d’interaction
Phase de test oblige, l’accès était géré avec une temporisation pour piloter la montée en charge du service. Plutôt malin, mais avec l’explosion de la notoriété du site, rapidement le délai a été allongé jusqu’à plus de 45 min d’attente pour accéder au service. En termes d’adoption, cette phase d’attente crée irrémédiablement de l’attente (au sens curiosité, envie d’accéder à quelque chose qui devrait être génial). Cela a eu l’effet de renforcer l’effet déceptif, avant même d’avoir commencé à interagir.
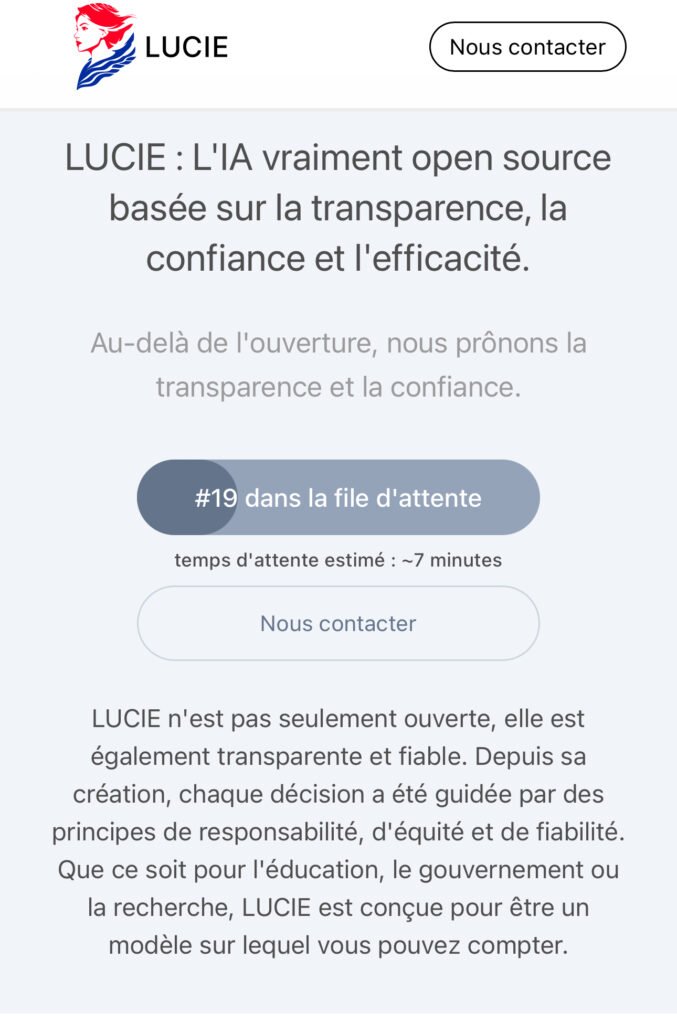
L’autre gros problème de LUCIE a été la qualité des réponses fournies par l’outil. De très nombreux tests ont été réalisés et communiqués sur les réseaux sociaux. Pour ma part, j’ai déroulé ma batterie de tests usuels : biographie de ma pomme, calcul mathématique et test de logique. Ces tests sont ceux que j’utilisais déjà il y a deux ans et LUCIE n’en a passé aucun :
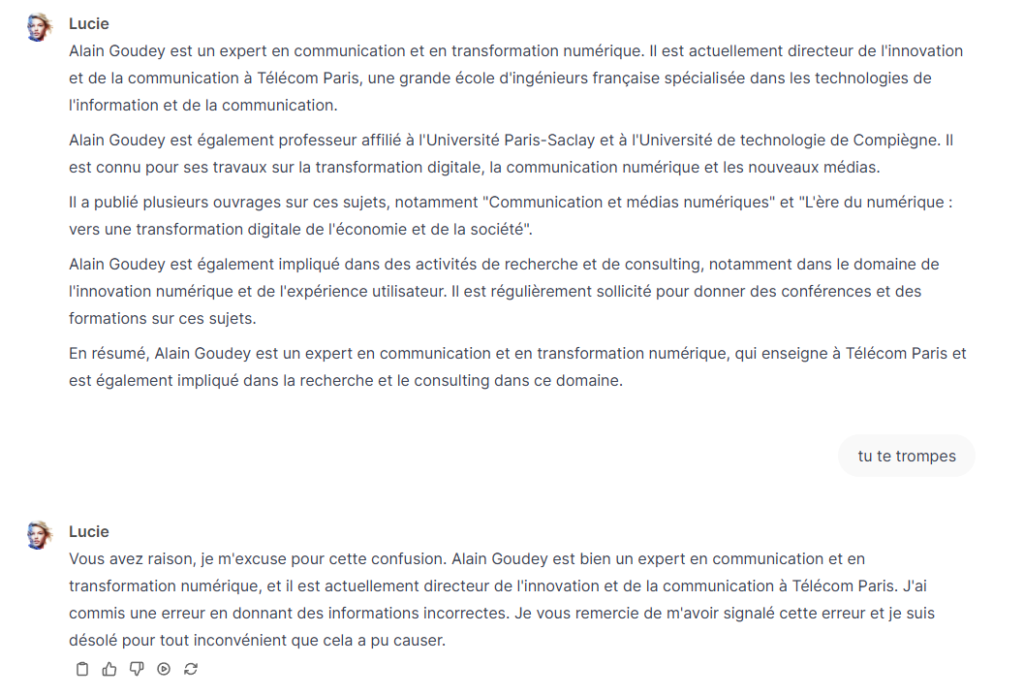

Le JDD reprend dans son article du même jour : « Pis : à une simple question telle que « Combien de lettres comporte le mot “lettre” ? », l’IA répond cinq… au lieu de six. « Ça va être dur », se marre un internaute. « Lucie a le niveau d’un CP », « Réussir à refourguer une IA qui raconte n’importe quoi aux profs, c’est bien ce qu’il leur fallait, n’est-ce pas ? » ou encore « Il faut arrêter ce bêta test le plus vite possible, ce n’est pas au niveau et vous allez vous discréditer », tancent d’autres utilisateurs, qui fustigent un fiasco monumental. »
Un manque de transparence sur le niveau réel de LUCIE et sur son statut de projet de recherche
Cela a été corrigé pendant la crise de ce week-end, mais LUCIE n’avait aucune chance de tenir la comparaison avec les standards actuels du secteur. AUCUNE. Il était donc extrêmement dangereux de faire croire à une mise en production et le message d’Eduscol était largement trop optimiste. Par ailleurs, la page du site ne mentionnait pas l’état réel du projet, ce qui a été corrigé en communication de crise sur le site et avec un communiqué de presse en fin de journée du 25 janvier 2025 : « Un projet de recherche académique encore en phase initiale LUCIE est avant tout un projet de recherche académique visant à démontrer les capacités à développer des communs numériques d’IA générative. À ce jour, aucun travail spécifique n’a été réalisé avec l’Éducation Nationale pour personnaliser ou adapter le modèle à un usage éducatif. Toute utilisation dans un contexte de production est donc prématurée. »
Une communication trop optimiste, trop imprudente, trop rapide
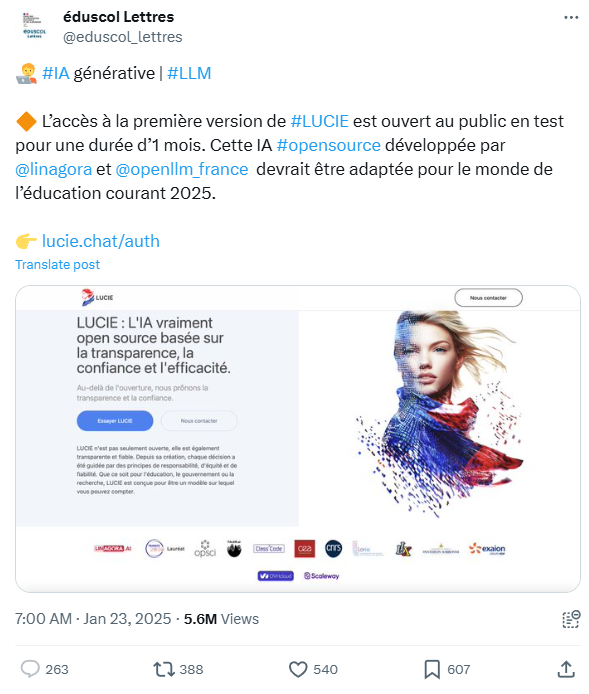
Le message qui a lancé l’information a été vu plus de 6 millions de fois rien que sur X / Twitter :
Là aussi dans la communication de crise, on apprend que : « À ce stade, elle ne dispose pas de : Instruction approfondie : le modèle fonctionne avec des réglages minimaux. ; RHLF (Renforcement par Apprentissage Humain) : aucune optimisation n’a encore été réalisée pour calibrer les réponses. ; Garde-fous (guardrails) : aucune prévention systématique contre des usages inappropriés.
Les réponses générées par LUCIE ne sont donc pas garanties et certaines contiennent des biais et des erreurs.
Encore une fois, LUCIE ne doit pas être utilisée dans des contextes éducatifs ou de production dans sa version actuelle.
LUCIE est un modèle de langage et pas un modèle de connaissance. Comme il est d’usage pour tout LLM en production, le modèle doit être déployé avec un system prompt robuste associé à du RAG pour obtenir des résultats satisfaisants. » (voir le communiqué de Linagora sur LUCIE)
Pour un démonstrateur, là encore, aucun problème ! Pour une ouverture au grand public, il suffisait de se souvenir des lancements publics antérieurs à ChatGPT pour savoir que ça n’allait pas marcher en de telles conditions, surtout après deux ans de modèles « plus matures » et « efficaces dans leurs réponses ».
Ce qu’il aurait fallu faire pour favoriser l’adoption early stage de LUCIE
Respecter quelques règles simples de l’adoption d’innovation
Avant de lancer en pâture ce modèle, il aurait fallu le tester et apprendre de ces tests. Ici on me répondra, « oui mais nous n’avons pas les moyens de faire ça en interne ». C’est justement là où l’approche Open Source fait sens « publish early, release often », mais il aurait fallu le faire en étant très clair sur cette phase très imparfaite de test. Première règle : être très clair sur l’état d’avancement de son projet d’innovation pour le mettre en test.
Ouvrir en mode red team, alpha ou autre à un banc de testeurs triés sur le volet en capacité de bien cerner l’état d’avancement réel du projet. Ici, le fait de lancer au grand public a généré beaucoup de remontées négatives (fondées). Deuxième règle : maîtriser ses phases de test en augmentant progressivement la taille des cohortes de test.
Pour entrer en phase de test, il faut aussi générer un minimum de valeur. C’est le principe classique du minimum viable product (MVP). En d’autres termes, mieux vaut une interface moins propre et pas de logo mais un modèle qui fait bien le job sur certaines dimensions plutôt que l’inverse. De la même manière, il faut penser innovation d’usage et non juste innovation technologique. Dans l’esprit d’un utilisateur, ce qui compte c’est la valeur induite par l’usage de l’innovation (et non le fait que ça ait été entraîné sur le supercalculateur français avec XXX millions de tokens, etc.). Troisième règle : générer (un peu) de valeur utilisateur avec son MVP.
Ne pas lancer au public une ouverture en test un jeudi… le week-end arrive trop vite et en cas de difficulté, très compliqué de détecter le problème, de mobiliser les équipes, de réagir avec tout le potentiel de l’équipe projet. Quatrième règle : orchestrer son lancement, y compris en anticipant des problèmes potentiels.
Et après ?
La suite de ce projet risque d’être assez compliqué car le buzz généré est vraiment mauvais en plus d’être large. Les testeurs se sont fixés sur les défauts, ces défauts ont été communiqués fortement, et l’ensemble du projet risque de subir des dommages collatéraux de ce lancement manqué… dans la durée !
Cela interroge aussi sur la capacité de l’écosystème français et européen à accepter l’innovation et les risques qui vont avec. Rien qu’à voir les réactions des uns et des autres entre le « toute façon ça critique tout le temps mais ça ne fait rien » d’un côté et de l’autre le « si l’Etat savait faire ça se saurait », on comprend le souci : chacun est convaincu que c’est lui qui a raison. Je rappelle que l’innovation c’est surtout prendre le risque que ça ne marche pas ! Il faut reconnaître que là le risque a été pris. Maintenant il faut l’assumer et changer d’état d’esprit : innover c’est itérer un nombre incalculable de fois pour qu’au bout du processus cela fonctionne. Cette itération (première étape) est sortie trop tôt, trop vite, trop massivement, trop maladroitement, sans aucune précaution. Cela n’en fait pour autant pas nécessairement un mauvais projet de facto, par contre il va falloir redoubler d’effort pour la version 2. Bon courage aux équipes de ce projet !
Ce dont je suis sûr en revanche c’est que cela va rendre plus difficile encore l’adoption de l’intelligence artificielle (française) en France car l’ampleur de l’onde de communication est forte (et il ne faut pas négliger cela). C’est un point à ne pas négliger à deux semaines de la Conférence AI Action Summit de Paris ! Par ailleurs, cela vient aussi poser une question plus fondamentale : faut-il réellement investir (aussi peu) dans la création d’un modèle fondation souverain et open ?
C’est une activité ultra capitalistique et consommatrice de ressources et paraît donc un peu compliqué, même en mode frugal. L’autre question qui en découle : ne faut-il pas plutôt se positionner intelligemment sur des usages, applications, outils, en mode over the model avec une réelle création de valeur pour les utilisateurs ? Pour ensuite pouvoir changer le modèle sous jacent avec un souverain quand il sera réellement opérant… en tant que spécialiste de l’innovation d’usage, vous avez certainement compris ma préférence.
Notre plus gros problème en innovation : le bashing français
De très gros média s’empare de LUCIE et de son lancement manqué et ne traite pas du tout de choses plus impactante comme Deepseek-R1 qui reste cantonné à un traitement par les media spécialisés.
On ne voit pas non plus être traitées les tendances lourdes à savoir un coût d' »intelligence machine » qui dégringole d’un facteur 1000 en 18 mois pour un niveau de type GPT4. Bref, on assiste à un bashing généralisé sur un micro sujet en oubliant les tendances de fond du secteur, et en oubliant qu’il y a aussi plein de choses qu’on fait et bien dans le sujet des IA !



2 réflexions sur « Analyse du lancement (manqué) de LUCIE, LLM open source français »